

Stack Overflow face à une révolte contre son accord avec OpenAI
-

Après la signature du contrat avec OpenAI permettant à l’entreprise d’entrainer ses grands modèles de langage sur les contenus publiés sur son site, Stack Overflow fait face à des utilisateurs mécontents qui ont essayé de supprimer leurs anciens posts. Le site a bloqué toutes les possibilités de retirer le contenu qu’il héberge.
En début de semaine dernière, Stack Overflow a annoncé la signature d’un contrat avec OpenAI. Mais depuis et comme l’a repéré The Verge, une partie de la communauté du site est en colère, certains utilisateurs s’opposent à ce que les questions et réponses qu’ils ont rédigées pendant des années soient vendues et utilisées pour alimenter l’entrainement des modèles d’OpenAI.
Ainsi, comme il l’explique sur son compte Mastodon, l’utilisateur benui a essayé en début de semaine dernière de supprimer ses réponses les mieux notées. Mais il s’est rendu compte que ce n’était pas possible, car Stack Overflow ne permet pas de supprimer des réponses acceptées considérant qu’elles participent à la connaissance bâtie par la communauté de ses utilisateurs.
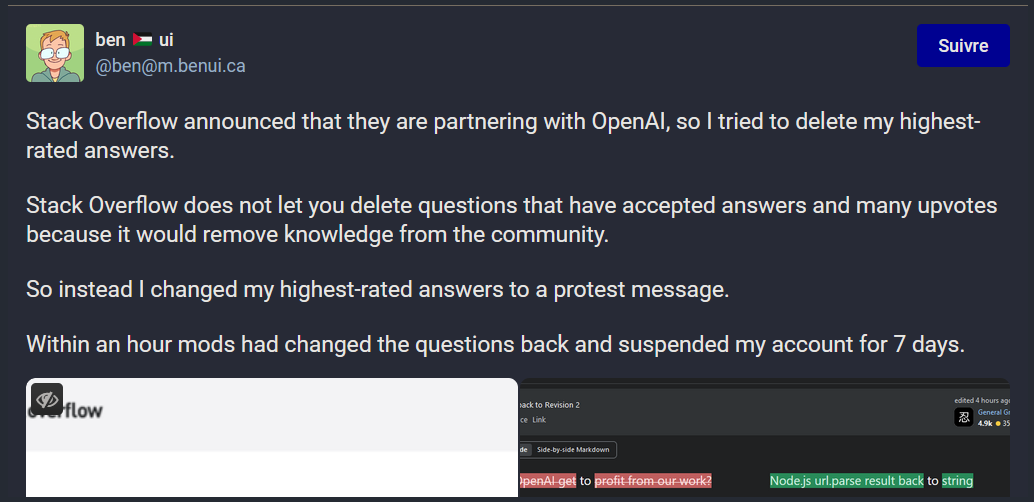
Benui a finalement décidé de modifier ses réponses en les remplaçant par un message critiquant l’accord avec OpenAI. Mais il explique qu’une heure après, des modérateurs avaient remis la réponse initiale et suspendu son compte pour 7 jours.
Questions et réponses sous licence Creative Commons BY-SA
Depuis, d’autres utilisateurs ont aussi témoigné de cette impossibilité de manifester son refus de l’utilisation de son contenu dans le cadre de l’accord entre Stack Overflow et OpenAI.
Les conditions générales du site expliquent que « vous ne pouvez pas révoquer l’autorisation donnée à Stack Overflow de publier, distribuer, stocker et utiliser ce contenu et de permettre à d’autres personnes d’avoir des droits dérivés pour publier, distribuer, stocker et utiliser ce contenu ».
Le site impose aussi à tous ses utilisateurs de la licence Creative Commons 4.0 BY-SA qui est la licence la plus permissive. Cette licence, utilisée aussi par Wikipédia, permet à n’importe qui, dans n’importe quel but, même commercial, de réutiliser le contenu.
Rappelons aussi qu’il existe déjà depuis quelques années un outil permettant de télécharger l’intégralité de Stack Overflow. Ce projet a été mis en place en collaboration avec le français Kiwix et récupère (« scrap ») les questions/réponses du site pour créer des versions « hors ligne ».
Même sans les accords commerciaux de Stack Overflow, des entreprises peuvent se servir d’une version hors ligne comportant toutes les questions/réponses en licence Creative Commons BY-SA pour entrainer leurs modèles.
Des utilisateurs qui se sentent trahis
Mais Christian Hujer, utilisateur du site, explique sous l’annonce de Stack Overflow que le problème pour lui va au-delà des aspects légaux : « je me sens bafoué, trompé, trahi et exploité ». Lui aussi ajoute qu’il va supprimer son compte, même s’il sait que ses questions et réponses ne seront pas supprimées avec.
Cette fronde des utilisateurs de Stack Overflow n’est pas sans rappeler celle qu’a connue Reddit l’année dernière contre le passage de son API en payant. Le réseau social a finalement réussi à « normaliser » la situation après des mois de remous au sein de sa communauté. On ne sait pas si le mouvement de protestation de la communauté de Stack Overflow va suivre cette voie et à quelle vitesse, mais ce genre d’accords risque de freiner les utilisateurs à participer à la vie de plateformes de ce genre.
Source : next.ink
-
Il y a quand même une naïveté déconcertante des utilisateurs quant à l’utilisation de leurs contributions. Leurs données sont précieuses pour l’IA et la licence Creative Commons rend leurs utilisations légales ; pourquoi OpenAI s’en priverait ?
-
Il y a quand même une naïveté déconcertante des utilisateurs quant à l’utilisation de leurs contributions. Leurs données sont précieuses pour l’IA et la licence Creative Commons rend leurs utilisations légales ; pourquoi OpenAI s’en priverait ?
@Indigostar C’est vrai, mais si on n’accepte pas les conditions de ces bandits ou des autres, comme google, on ne peut même plus téléphoner, sauf sur un dumbphone.
")
Bonjour ! Vous semblez intéressé par cette conversation, mais vous n’avez pas encore de compte.
Marre de refaire défiler les mêmes messages ? Créez un compte pour retrouver votre position, recevoir des notifications des nouvelles réponses, sauvegarder vos favoris et voter pour les messages que vous appréciez.
Grâce à votre participation, ce message peut devenir encore meilleur 💗
S'inscrire Se connecter