
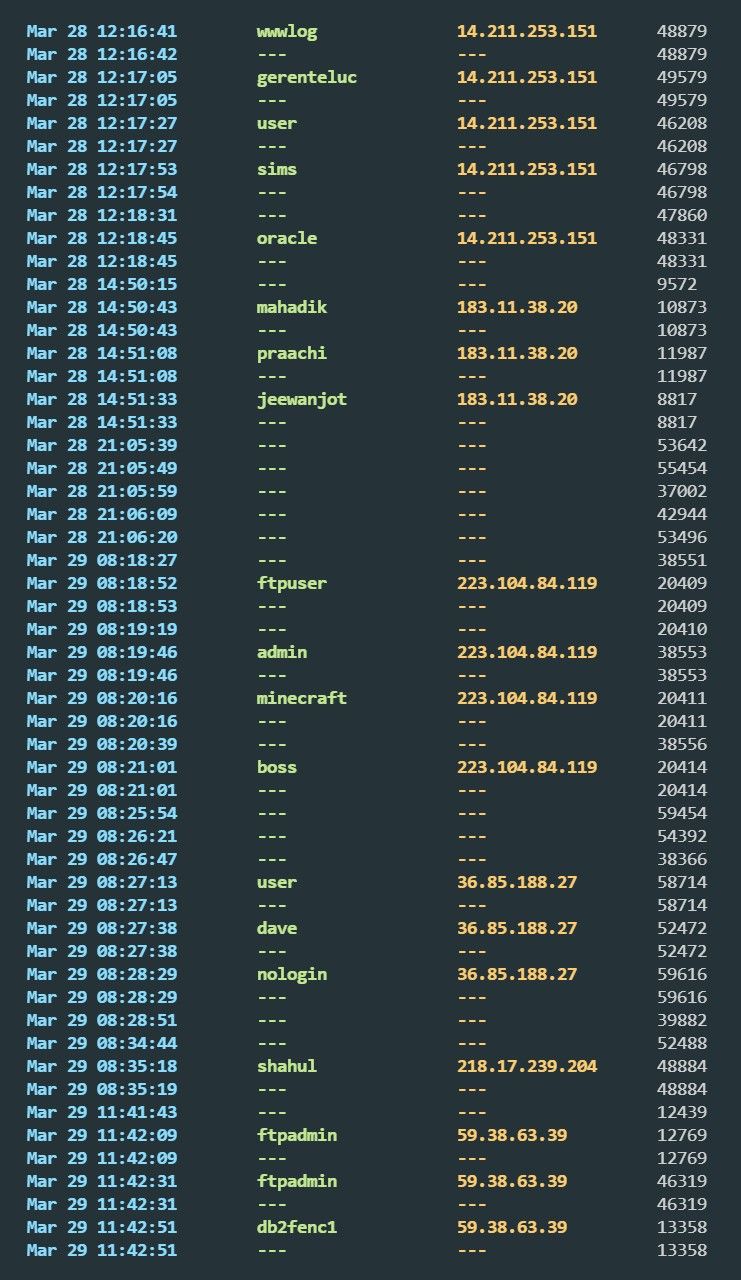
Live jour 3
Avec une vue en direct sur le module

 Ils contrôlent l’univers du forum et ils gouvernent le vaisseau numérique, de l’interface à l’hyperespace à travers les astres et les champs de données. Leur devise : "Un reboot pour rétablir la paix, un ban pour éliminer la menace""
Ils contrôlent l’univers du forum et ils gouvernent le vaisseau numérique, de l’interface à l’hyperespace à travers les astres et les champs de données. Leur devise : "Un reboot pour rétablir la paix, un ban pour éliminer la menace""
j’avais pas vu ca comme ca mais tu as raison @michmich maintenant je ne vois que ca !!

MDR :
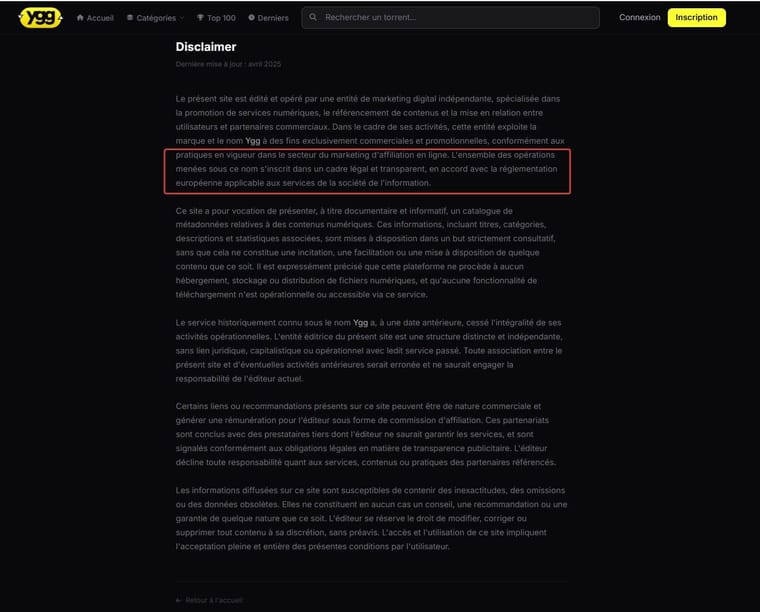
N’oublions pas de d’ajouter: achat illégal et utilisation illégale d’une BDD illégale et soutirer de l’argent oux teubés qu’iront se connecter et se feront avoir 
Tiens tiens
Ce n’est pourtant pas le 1er avril 
Les blagues les plus courtes sont les meilleures…

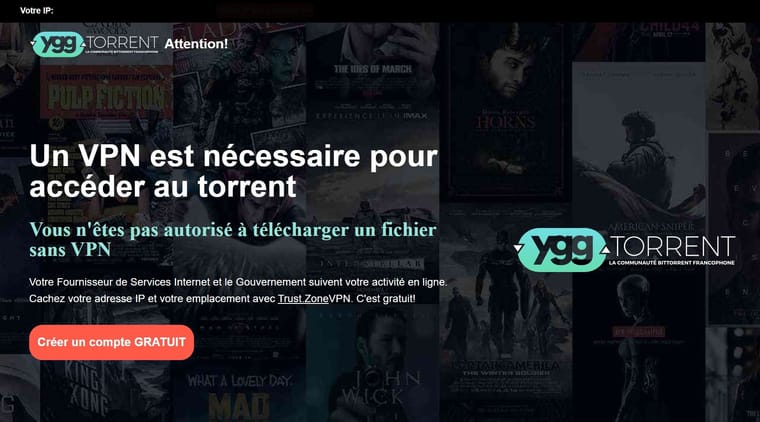
EDIT: C’est juste pour l’info. N’allez pas laisser trainer vos pattes là-bas. 
J’avoue, c’est sans fin 
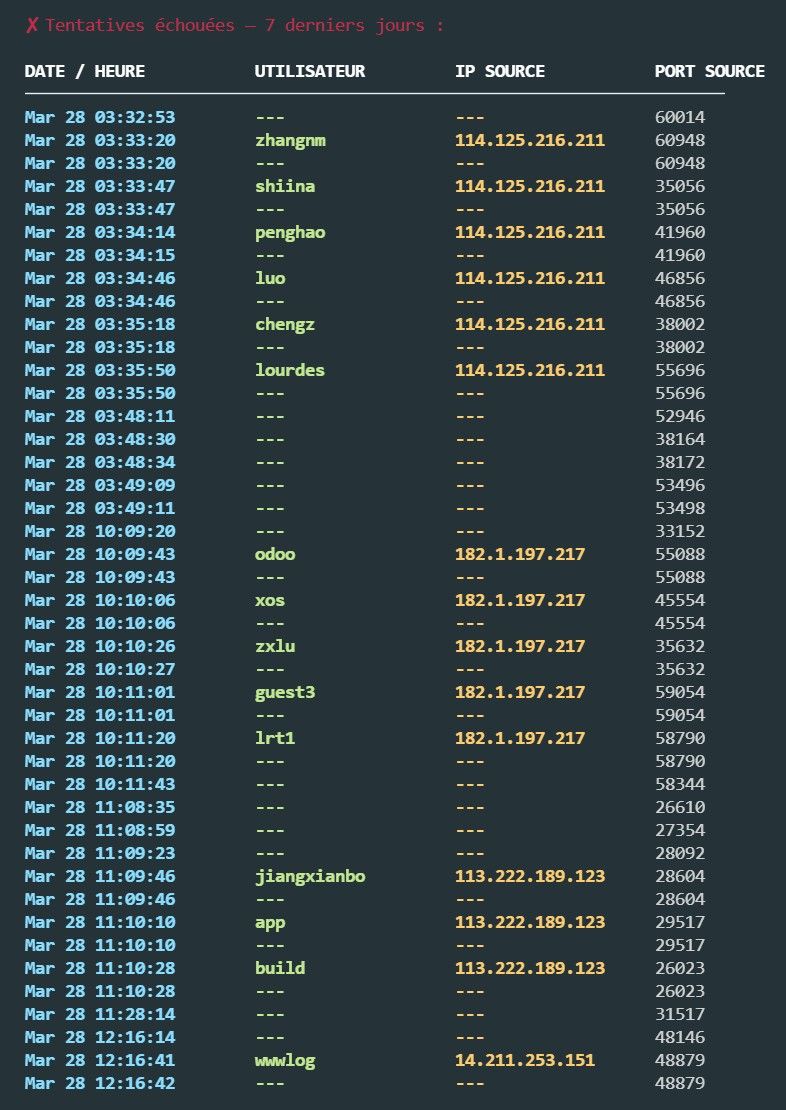
Perso, entre autre, je fais ceci pour SSH :
PermitRootLogin no
Port xxxx
PubkeyAuthentication yes
PermitEmptyPasswords no
PasswordAuthentication no
AllowUsers user1@ip1 user1@ip2 user2@ip1 user2@ip2
Puis j’ajoute un IDS qui me ban tout ça sur iptables via crowdsec ou un jail Fail2ban.
mes ports exposés à l’internet contrairement à ces VPS
Hetzner à un firewall qui fonctionne bien pour les VPS je trouve :
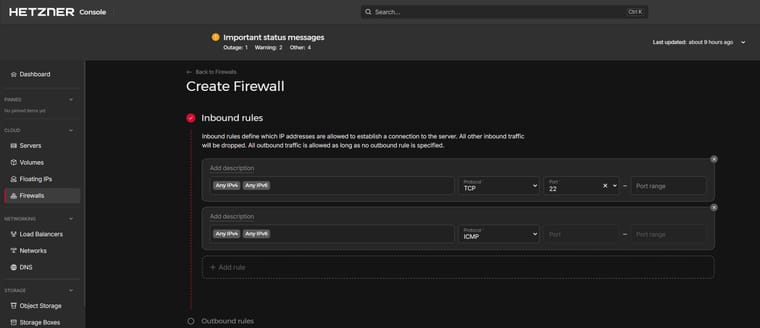
")
