Bonne années! Et puisse le sort vous être favorable !
Networld
@Networld
Messages
-
Bonne année 2026, même si… -
[Tendance No Kids] Exit les chiards hurlants…J’en ai 4, alors forcément contre. Ça fait partie de la vie et c’est oublier que tous les adultes ont été des enfants. Le problème, ce ne sont pas les enfants, ce sont les parents qui ne s’en occupent pas. Le nombre de fois que des gens nous on jeté des regards lorsque nous arrivons, dans un avion, sur un vol de 8h par exemple.
Mais fait complètement dingue, si, au lieu de passer 8h le nez sur l’écran ou son iPad, tu joues à tes enfants, lits des histoires, etc…, ça se passe très bien! Alors oui, c’est moins tranquille, mais c’est ça être parent.
Avoir des enfants, ce n’est pas s’en occuper par intermittence lorsque ça arrange, mais tout le temps! Et ça marche très bien. Ça m’agace surtout d’en voir certain le nez sur leur téléphone (parents) ou les laisser sans surveillance, du coup ça m’est arrivé un certain nombre de fois de “gentiment gronder” (des enfants donc) parce qu’ils font n’importe quoi, avec un de ces parents à 5m qui ne fait rien…
Donc la solution exclure des enfants parce que des parents ne gèrent pas…C’est le monde à l’envers. Et sinon il existe de très bons écouteurs et casques antibruits

-
[Tendance No Kids] Exit les chiards hurlants…Côté CFF (trains suisses) il y a une bien meilleure alternative je trouve. Sur certaines lignes, il y a des voitures (@patricelg, j’ai bien lu :)) silence. Personne n’est interdit de s’y rendre, il suffit d’être silencieux. Oui j’y suis déjà allé avec mes enfants, suffit de leur expliquer et ça marche très bien. Et oui oui, ils sont normaux et on les drogue pas

“Les enfants, c’est wagon (pardon) silence aujourd’hui, tenez-vous bien et on ira faire les 4h dans une boulangerie sympa.”, ça marche très bien!
Il y a d’autres endroits réservés pour les adultes et j’ai du mal avec ce concept. Même sans enfants, je n’y mettrai pas les pieds. Je ne parle pas où c’est le cas pour des raisons légales, ça c’est différent.
Je trouve que notre société devient de plus en plus intolérante à certains aspects de la vie courante. Surtout face aux enfants. Le nombre de fois où lorsque l’on va dans un restaurant tous les 6 (et qu’il y a que des tables à 4), on a l’impression de déranger parce qu’il faudrait déplacer une table… On s’excuse, on vient dépenser des sous chez vous…
Et oui il y a la première classe. Mais si tu paies, tu y accèdes, c’est le principe. J’y vais lorsque je suis seul (parce 6 billets en première…
 ). Le voyage sera de toute manière plus tranquille vu qu’il y a moins de monde et que la majorité sont ceux qui voyagent pour le boulot. Mais s’il y a des enfants et bien il y a des enfants. S’ils font du bruit, ben ils font du bruit. Je mets mes écouteurs antibruits et c’est tout.
). Le voyage sera de toute manière plus tranquille vu qu’il y a moins de monde et que la majorité sont ceux qui voyagent pour le boulot. Mais s’il y a des enfants et bien il y a des enfants. S’ils font du bruit, ben ils font du bruit. Je mets mes écouteurs antibruits et c’est tout.Les enfants, c’est notre avenir. Si notre société leur montre qu’ils ne sont pas les bienvenues juste parce que ce sont des enfants, pour le confort de quelques personnes maintenant, ça donnera quoi plus tard lorsqu’ils seront adultes? Ca me donne la même impression que les écrans. Refile un écran à chaque temps mort et moment qui t’arrange…Ca va vraiment en faire un enfant calme lorsqu’il en aura pas…
-
[Docker Apps] BookHub : Automatisation DL ebooks et traitementHello,
Suite au différents évènements sur un certain Y machine truc, comme beaucoup, j’ai cherché des alternatives. Je suis assez rapidement tombé sur ce forum et j’ai commencé à lire et à un peu participer. Et il faut dire qu’il y a du contenu très intéressant. J’ai d’ailleurs modifié ma SeedBox suite à une discussion (coucou @Aerya), installé RustDesk (coucou @Raccoon), prévu d’installer Veeam (coucou @Violence) et d’autres choses sont en attente.
Ensuite j’ai eu pas mal de demandes pour des ebooks, de la musique et des livres audio de la part de ma belle maman, ma maman, ma femme, deux de mes filles et une amie de la famille qui vit en Australie. Et qu’est-ce que fait un flemmard dans ce genre de cas? Trouver des solutions qu’il peut gérer à distance. Installer une fois ce qu’il faut et gérer tranquillement depuis son canapé
")
C’est là que j’ai découvert Kavita (pour envoyer sur des Kindle), Audiobookshelf, Prologue, ShelfPlayer, etc… Et ma nouvelle meilleure amie Anna pour les eBooks (découverte sur ce forum pour changer).
Tout ça c’est bien. J’ai fait une note partagée par personne, comme wishlist et je me suis vite retrouvé avec pratiquement 100 titres rapidement (oui, ça lit beaucoup chez nous et plus de place dans les bibliothèques, pourtant il y en a beaucoup…). Cool, mais chercher manuellement, c’est long, corriger toutes les méta données pour un affichage propre dans Kavita, c’est long.
N’ayant pas trouvé une solution qui me convenait complètement, j’ai décidé de m’amuser un peu avec l’IA. Tout d’abord Perplexity (une catastrophe le résultat), puis ChatGPT.
**DISCLAIMER** : je ne sais pas coder! Mes connaissances se limitent au CSS et HTML il y a 15 ansC’est là qu’est né le projet Autothèque. Oui le nom est moche. Entièrement réalisé avec ChatGPT, ce qui a pris un certain nombre d’heures avec une IA qui avait tendance à partir dans tous les sens et faire des modifications foireuses.
But du projet :
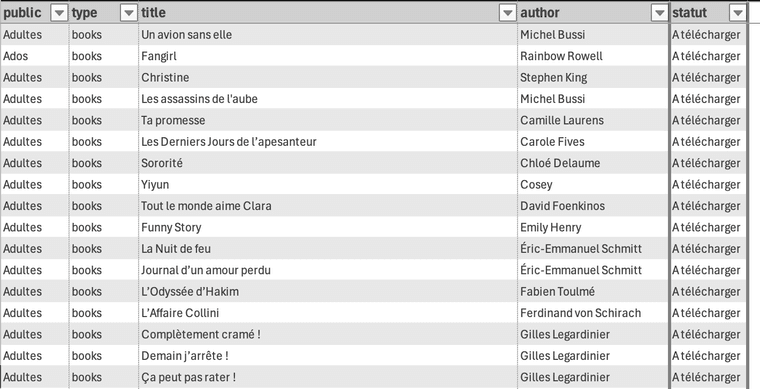
- Avoir une Wishlist (doc Excel dans mon NextCloud) que je remplis avec “Public, Type, Titre, Auteur, Statut”
- Pouvoir lancer automatiquement ces DL d’ebooks chez ma copine Anna ou autre source
- Ensuite correction des méta données automatiquement (Titre, Auteur, Série)
- Pour finir trier les ebooks dans les bonnes bibliothèques
Tout cela avec 0 intervention humaine mis à part le remplissage de la Wishlist.
Dans Kavita j’ai 3 bibliothèques :
- Adultes
- Ados
- Enfant
Pour cela qu’il y a “Public” dans ma wishlist. Il y a aussi “Type”, pour “books, audiobooks, comics”. Je n’exclus pas que ça fasse aussi partie du projet par la suite. Pas utile pour le moment.
Est-ce que ça a marché? Euh…si je dis :
- Plusieurs crashs complets de docker

- docker.img corrompu

- Freeze de HDD sur mon NAS

- Plantage complet de UnRAID (devenu tellement lent)

Vous en dites quoi ?

Je vous l’avais dit, je ne sais pas coder. Donc, ça c’était la V1. Mais avec cet échec, j’étais bien plus au clair sur les problèmes, ce qui n’a pas fonctionné et la structure. C’était trop complexe, exécution trop lente, mais beaucoup d’I/O (freeze les HDD…).
C’est parti pour la V2 avec quelques heures passées avec ChatGPT uniquement pour définir la structure, les bases du fonctionnement et définir une ligne claire pour qu’il ne dévie plus!
BookHub
Est-ce que le nom existe déjà? Aucune idée

C’est comme qu’est né BookHub. Enfin! Il n’est pas parfait, certainement largement améliorable sur plusieurs points et finalement encore en test.
La première étape a été de définir mon cachepool SSD comme base pour BookHubEnsuite voilà un résumé du projet fait pas mon nouveau pote ChatGPT.
 BookHub — Automatisation complète de gestion d’eBooks
BookHub — Automatisation complète de gestion d’eBooks(ShelfMark → Calibre → Kavita)
 Objectif
ObjectifBookHub est une chaîne d’automatisation personnelle permettant de :
- partir d’une wishlist simple (Excel)
- rechercher et télécharger automatiquement des eBooks via ShelfMark
- normaliser les fichiers avec Calibre
- produire une bibliothèque finale propre
- exposer cette bibliothèque à Kavita
- tout en limitant volontairement les I/O
BookHub n’est pas un gestionnaire de téléchargement,
n’est pas une bibliothèque,
 c’est un orchestrateur fiable et déterministe.
c’est un orchestrateur fiable et déterministe.
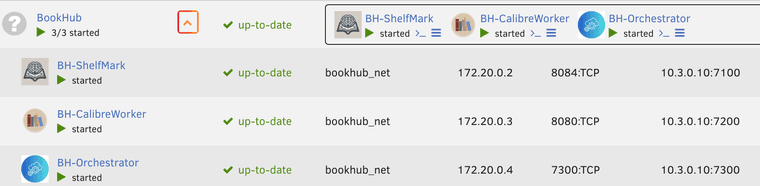
🧱 Conteneurs utilisés
BH-Orchestrator
→ scripts Python BookHub
→ gestion des états
→ dashboard HTMLBH-ShelfMark
→ recherche & téléchargement des eBooksBH-CalibreWorker
→ Calibre
→ normalisation
→ export finalKavita
→ lecture des bibliothèques finales
🧠 Principes clés
- Un script = une responsabilité
- Un cycle = un livre maximum
- Aucune action implicite
- Historique conservé
 ️ Arborescence principale
️ Arborescence principale/BookHub ├── 00_Wishlist │ ├── wishlist.xlsx │ └── _snapshots/ │ ├── 10_Inbox │ ← téléchargements ShelfMark │ ├── 20_Queue │ ├── Adultes │ ├── Ados │ └── Enfants │ ├── 95_State │ ├── jobs.json │ ├── queue.json │ ├── dashboard.html │ ├── dashboard.css │ └── runner.lock │ ├── config │ ├── snapshot_wishlist.py │ ├── read_wishlist.py │ ├── build_queue.py │ ├── resolve_and_trigger_shelfmark_v2.py │ ├── scan_inbox.py │ ├── move_to_calibre_queue.py │ ├── process_one_calibre.py │ └── runner.py │ └── Ebooks ├── Adultes/Livres ├── Ados/Livres └── Enfants/Livres
 Gestion par Public
Gestion par PublicChaque livre est classé dans un public :
AdultesAdosEnfants
Le public détermine :- la file d’attente
- la bibliothèque finale
- la bibliothèque Kavita
 Wishlist (point d’entrée)
Wishlist (point d’entrée)/BookHub/00_Wishlist/wishlist.xlsx
- simple Excel
- aucune logique métier
- snapshot automatique à chaque cycle
🧾 Scripts BookHub (et leur rôle)
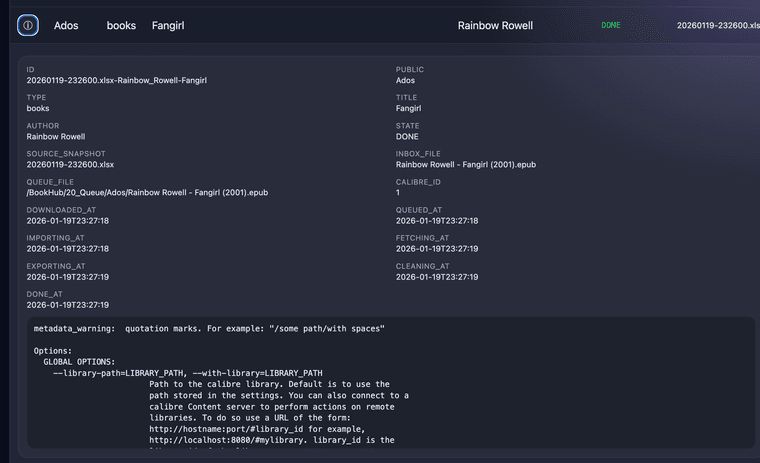
1️⃣ snapshot_wishlist.py
- fige la wishlist
- garantit la traçabilité
2️⃣ read_wishlist.py
- transforme la wishlist en jobs
- état initial :
NEW
3️⃣ build_queue.py
- construit la queue
- préserve l’historique
4️⃣ resolve_and_trigger_shelfmark_v2.py
- recherche via ShelfMark
- déclenche le téléchargement
- état :
DOWNLOADING
5️⃣ scan_inbox.py
- détecte les fichiers téléchargés
- matching tolérant
- état :
DOWNLOADED
6️⃣ move_to_calibre_queue.py
- déplace vers
20_Queue/{Public} - état :
READY_FOR_CALIBRE
7️⃣ process_one_calibre.py
- import Calibre
- fetch metadata
- export final
- nettoyage complet
- état final :
DONE
8️⃣ runner.py
- orchestre tous les scripts
- lock anti double-run
- conçu pour cron / Unraid User Scripts
 ️ Ordre d’exécution
️ Ordre d’exécution→snapshot_wishlist.py
→read_wishlist.py
→build_queue.py
→resolve_and_trigger_shelfmark_v2.py
→scan_inbox.py
→move_to_calibre_queue.py
→process_one_calibre.py
 Bibliothèque finale (Kavita)
Bibliothèque finale (Kavita)/BookHub/Ebooks/{Public}/Livres
- fichiers propres
- métadonnées normalisées
- source unique
- Calibre utilisé uniquement comme outil
🧹 Politique de nettoyage
Après export :
- suppression du livre dans Calibre
- suppression du fichier source
- aucune duplication
- cache maîtrisé
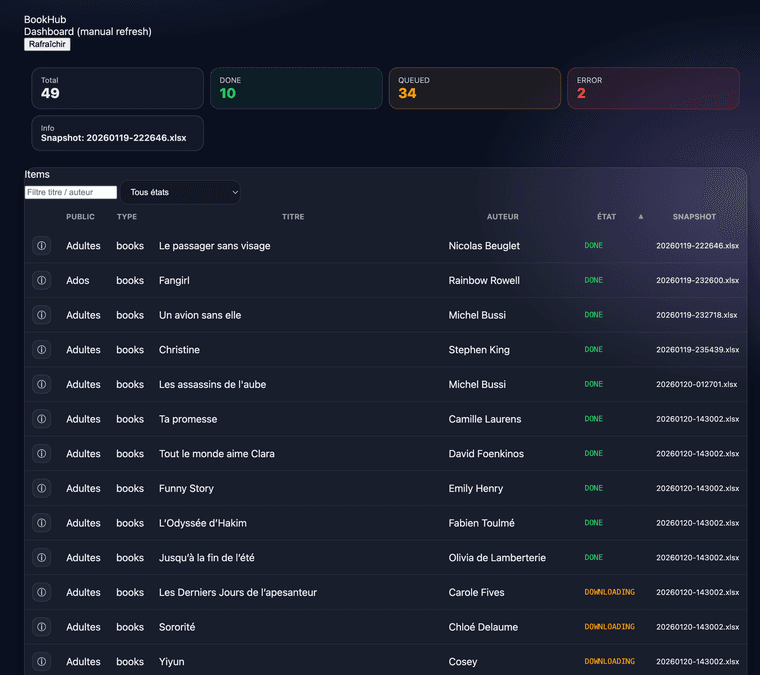
 Dashboard
Dashboard- HTML + CSS séparé
- lecture directe de
queue.json - responsive
- filtres
- états colorés
- aucune écriture
 Évolutions possibles
Évolutions possibles- actions depuis le dashboard
- CSS avancé
- statistiques
- règles spécifiques par public
 État du projet
État du projet ️ Téléchargement automatisé
️ Téléchargement automatisé
️ Matching robuste
️ Normalisation Calibre
️ Export Kavita
️ Dashboard stable
️ Historique conservé
 BookHub privilégie la stabilité, la compréhension et la maîtrise des flux.
BookHub privilégie la stabilité, la compréhension et la maîtrise des flux.
Est-ce que ça fonctionne?
Apparemment oui
Il y a certainement des améliorations à apporter. Ce sera son utilisation qui permettra de mettre le doigt sur ce qui peut coincer.Mais surtout :
- Pas de crash complet de docker
- docker.img pas corrompu
- pas de freeze HDD (de toute façon c’est sur mon cachepool SSD)
- Pas de plantage complet de UnRAID
Je mets les livres dans ma Wishlist (xlsx) et les téléchargements se lancent petit à petit via ShelfMark et je retrouve les ebooks dans la bonne bibliothèque au final. Aucun problème d’en mettre 100, puisqu’il en gère un par run.
Ce qu’il faudra certainement améliorer :
- Gestion des erreurs
- Meta données pas si propres que ça, donc classement final pas toujours parfait
- Voir si les séries sont bien gérées
A quoi ça ressemble ?
Les conteneurs :
La Wishlist :
ShelfMark (rien de particulier) :
Le dashboard pour le suivi :
Pourquoi avoir posté tout ça? Parce que j’aurai bien aimé tomber dessus
J’ai découvert pas mal de choses intéressantes ici, ce qui m’a permis de lancer certaines choses ou parfaire certains services. Et ce n’est que le début.Précisions :
- Un livre est ajouté dans la wishlist et lorsque statut passe en “A télécharger”, ça lance l’automatisation, dans le cas contraire -> ignoré
- Pas de retour dans la wishlist, sert uniquement de base
- Le traitement ensuite pas le conteneur orchestrateur a volontairement des limites, 1 livre par lancement (cron via User Script). Cela permet d’éviter des problèmes d’I/O trop importants. Pour le moment en tout cas.
- Pour le moment le dashboard ne permet pas encore de piloter quoi que ce soit. J’aimerai que ce soit le cas, comme supprimer un livre de la wishlist (suite à une erreur)
- Calibre est piloté vis des scripts, donc pas grand chose à configurer de son côté.
C’est quoi la suite ?
Je ne sais pas trop. Des améliorations de toute façon pour que ça demande le moins de maintenance possible et simplement profiter des ebooks -
[Topic Unique] [Fr] HD-F@lefish
Je suis plutôt un utilisateur discret. Du seed, mais peu de participation. Donc pas évident d’avoir des entrées par-ci par-là. Pour HD-F j’ai reçu une invitation et c’est coolDepuis YGG je me suis mis sur plusieurs trackers (9…) et mis en seed ce que je pouvais pour garantir un certain ratio. Cela permettra de voir comment ça évolue. Le dernier objectif c’est Valentine, mais là…

En tout cas côté HD-F, c’est plutôt sympa le contenu, je vais m’y plaire
-
[Docker Apps] AudioHub - Gestion des audiobooksAprès BookHub, voici AudioHub. Le fonctionnement est très similaire et la stack presque identique.
J’aime beaucoup les livres audio, et ma famille aussi. Mais les gérer proprement, c’est chronophage. Je voulais un système qui fasse tout automatiquement :
- Détecter un audiobook téléchargé et l’enregistrer en base de données
- Récupérer les métadonnées depuis plusieurs sources et garder les meilleures (titre, auteur, série, index de série, synopsis…)
- Éviter que le narrateur se retrouve comme auteur — problème fréquent avec les livres audio
- Convertir en .m4b les livres en .mp3, en préservant et renommant les chapitres
- Écrire toutes les métadonnées dans le fichier, couverture incluse — comme ça si je change de gestionnaire de bibliothèque, les infos sont déjà dans le fichier
- Prendre en compte le public cible (Adultes, Ados, Enfants) basé sur les catégories qBittorrent
- Déplacer le fichier dans la bibliothèque finale selon une hiérarchie fixe
J’avais initialement prévu d’utiliser Ollama en local pour trier la pertinence des sources et enrichir les métadonnées. Malheureusement, les modèles que je peux faire tourner sur ma RTX 5060 ne sont pas assez fiables pour cette tâche — les résultats étaient trop aléatoires. J’ai donc opté pour des scripts classiques avec des sources bien définies.
C’est à nouveau Claude qui a été utilisé pour développer le projet. Après plus de 220 tests — un test = un livre audio traité de bout en bout — le système tourne bien et gère correctement la grande majorité des cas.

 ️ La stack -> tout est auto-hebergée
️ La stack -> tout est auto-hebergéeOutil Rôle 
n8n (self-hosted) Orchestration des workflows  ️
️Baserow Suivi du statut de chaque audiobook 
m4b-tool (sandreas/m4b-tool) Conversion MP3 → M4B + métadonnées AudioBookShelf Bibliothèque finale 
Google Books / OpenLibrary / Wikidata / Scraper “maison” Sources de métadonnées 
 Les 3 workflows
Les 3 workflows- Scanner — détecte les nouveaux dossiers dans qBittorrent et les copie dans une inbox
- Metadata — enrichit les métadonnées depuis plusieurs sources web
- Processor — convertit, vérifie, tag et place le fichier final dans la bibliothèque
Les workflows 2 et 3 se basent sur le statut Baserow pour savoir quoi traiter. Il est donc possible de modifier manuellement un statut pour forcer un retraitement à n’importe quelle étape.
1 — Workflow Scanner

3 dossiers qBittorrent sont scannés en source brute : Adultes, Ados, Enfants. Pour chaque nouveau dossier audio détecté, une ligne est créée dans Baserow. Le statut initial est Détecté.
Pour limiter l’I/O sur le cache SSD, au maximum 2 copies sont effectuées simultanément.
n8n

Baserow

2 — Workflow Metadata

Le workflow traite tous les items au statut Détecté ou En attente métadonnées. Il parse le nom du dossier source pour nettoyer les tags de qualité (
[mp3-128],[128Kbps],NoTag…) et interroge 4 sources en parallèle pour récupérer les métadonnées.Le statut À vérifier est intentionnel : avant que la conversion soit lancée, je jette un œil dans Baserow et je corrige si besoin (mauvaise série détectée, titre ambigu…). Une fois validé, je passe manuellement à Métadonnées OK.
n8n

3 — Workflow Processor

Le workflow traite les items au statut Métadonnées OK.
Après conversion, les chapitres sont vérifiés via
mp4chaps: on compare le nombre de MP3 source avec le nombre de chapitres dans le M4B. Si ça ne correspond pas, le fichier est supprimé et la conversion est relancée.Le bitrate source est préservé : 64 kbps → 64 kbps, 128 kbps → 128 kbps. Pas de recompression inutile.
Pour les tags, un détail qui change tout dans AudioBookShelf :
Tag Valeur Usage artistAgatha ChristieAffichage albumartistChristie, AgathaRegroupement sortartistChristie, AgathaTri alphabétique Sans ça, ABS crée des doublons d’auteurs et trie n’importe comment.
n8n

Statuts Baserow
Chaque statut peut être modifié manuellement pour forcer un retraitement. Par exemple, repasser un item de Erreur à Métadonnées OK relance directement la conversion au prochain cycle.
Si un item reste bloqué en En conversion plus d’1h (timeout n8n), il est automatiquement remis en Métadonnées OK pour relancer — plus besoin d’intervenir manuellement.
 Hiérarchie finale
Hiérarchie finale/Livres audio/Adultes/Livres audio/ ├── Christie, Agatha/ │ ├── Les quatre/ │ │ └── Les quatre.m4b │ └── Hercule Poirot/ │ ├── 01 - Les quatre/ │ └── 06 - Le Train Bleu/ └── Martin, George R.R/ └── Le trône de fer/ ├── 01 - Le Trône de Fer/ └── 02 - Le donjon rouge/
Résultat après quelques jours- ~170 audiobooks traités automatiquement
- ~15 nécessitaient une correction manuelle des métadonnées
- ~10 marqués “Introuvable” (noms de dossiers trop cryptiques)
-
[Topic Unique] Les films que vous avez aimés et/ou adorés@patricelg a dit dans [Topic Unique] Les films que vous avez aimés et/ou adorés :
Vous devriez bien aimer Blink Twice (2024) alors
")
https://www.allocine.fr/film/fichefilm_gen_cfilm=293674.html
Dispo sur Prime Video
Il est dingue ce film, j’ai beaucoup aimé !
-
[Tendance No Kids] Exit les chiards hurlants…@duJambon a dit dans [Tendance No Kids] Exit les chiards hurlants… :
Personnellement, ça m’est égal, dans un cas extrême, je me suis mis à chouiner plus fort que le môme et à me rouler par terre, ça l’a calmé direct

J’ai encore ses yeux ronds et sa tronche d’ahuri en mémoire et quand j’y pense ça me fais bienrigoler…
J’ai fait pareil à la sortie d’une activé, dans le parking en gravier. Ca a stoppé net sa crise

-
[Topic Unique] [Fr] C411 -
[Docker Apps] BookHub : Automatisation DL ebooks et traitement -
[Tendance No Kids] Exit les chiards hurlants…@BahBwah pas cool, c’est sur. Mais de là à interdire des voitures à des enfants… Pas très juste que pour une minorité la majorité soit pénalisée. Même si c’est dans l’air du temps
-
[Docker Apps] BookHub : Automatisation DL ebooks et traitement BookHub – Mise à jour du projetJe pensais pouvoir encore éditer mon premier message, mais apparemment non

Il y a du nouveau pour BookHub.
Le projet a beaucoup changé dans son fonctionnement et dans les scripts utilisés, mais pas dans le but !Suite à beaucoup de tests, des problèmes ont été corrigés, des améliorations faites et une certaine simplification.
Je souhaitais aussi éditer les métadonnées et que ce soit cohérent pour tous les ebooks. Constatation faite : avec Calibre, je ne parvenais pas à avoir des métadonnées cohérentes et surtout une gestion très aléatoire des séries.
 Les nouveautés
Les nouveautés- Corrections de bugs
- Simplification de certains scripts
- La wishlist devient LA vérité pour toutes les infos
(public, titre, auteur, série, index série, ISBN) - Ce n’est plus Calibre qui intègre les métadonnées, mais ebook-meta
(inclus dans Calibre) qui écrit les métadonnées dont la source est la wishlist - Export des epub dans les bibliothèques Kavita, selon le public
(ados, adultes, enfants) - Gestion des séries, importante pour la hiérarchie de la bibliothèque Kavita,
avec renommage des epub :
01 - Titre.epub,02 - Titre.epub - Inclusion de dossiers pour y mettre manuellement des ebooks, afin qu’ils suivent le reste de l’automatisation, en cas de difficulté à les trouver avec ShelfMark
- Une erreur ne bloque jamais la suite
(téléchargement, métadonnées, etc.) - Les ebooks qui ne sont pas trouvés sont mis en cooldown durant 3h après 5 essais
Ce qui donne au final- Une bibliothèque bien rangée
(facile de changer d’outil par la suite) - Des métadonnées propres et cohérentes
- Une automatisation complète depuis l’introduction des infos dans la wishlist
- La wishlist se trouvant dans mon home NextCloud, je l’édite facilement depuis n’importe lequel de mes appareils
Le déroulementWishlist.xlsx │ ▼ Snapshot Wishlist │ ▼ Queue (queue.json) │ ▼ Téléchargement (ShelfMark) │ ▼ /BookHub/10_Inbox │ ▼ /BookHub/20_Calibre_Inbox │ ▼ Écriture métadonnées (ebook-meta) │ ▼ /BookHub/30_Calibre_Outbox │ ▼ Export vers Kavita │ ▼ /Ebooks/<Public>/Livres/...
Hiérarchie finale dans la bibliothèque Kavita/Ebooks/ └── Adultes/ └── Livres/ ├── [censored], Stephen/ │ ├── Carrie.epub │ └── Shining.epub │ ├── Larsson, Stieg/ │ └── Millénium/ │ ├── 01 - Les Hommes qui n’aimaient pas les femmes.epub │ ├── 02 - La Fille qui rêvait d’un bidon d’essence.epub │ └── 03 - La Reine dans le palais des courants d’air.epub │ └── Jordan, Robert/ └── La Roue du Temps/ ├── 01 - L’Œil du monde.epub └── 02 - La Grande Quête.epub
D’où viennent les infos de la wishlist ?Je n’ai pas trouvé une meilleure solution que :
- Dans ma wishlist, je remplis auteur et titre
- J’ai une feuille qui contient ça au format
Auteur - Titre - Je donne un contexte dans une conversation avec ChatGPT en mode agent
pour qu’il cherche toutes les infos dont j’ai besoin en lui indiquant quelles sources utiliser
(≈ 4 minutes pour 20–30 titres) - Il me génère un XLSX
- Je fais ensuite un simple copier-coller dans ma wishlist
 Des améliorations en vue ?
Des améliorations en vue ?- Le dashboard
Comme il y a eu beaucoup de modifications et que je ne l’utilise plus vraiment,
j’aimerais l’exploiter pour piloter :- erreurs
- relancer
- reset
- ignorer
- ajout manuel
- Améliorer la source (wishlist) pour encore plus automatiser
Par exemple une wishlist self-hosted dans laquelle une IA serait connectée
(hébergée en local) dont le seul travail serait de remplir toutes les infos de la wishlist
avec uniquement auteur et titre- retour de l’état dans la wishlist (surtout lorsque complètement traité)
- ShelfMark n’est pas très efficace
Il peine à trouver certains ebooks alors que je les trouve facilement chez Anna directement
→ à creuser
Possible que le fonctionnement avec l’IA soit un peu lourd, mais cela me permettrait ensuite d’implémenter probablement aussi la gestion des livres audio et des BD.
Le but étant de pouvoir changer facilement d’outils
(Kavita, Audiobookshelf, etc.) si nécessaire.
Avec une bonne hiérarchie de dossiers et des métadonnées complètes, ce ne sera pas un problème. -
[Tendance No Kids] Exit les chiards hurlants… -
[Docker Apps] BookHub : Automatisation DL ebooks et traitement BookHub continue d’évoluer !Voici les dernières améliorations apportées au projet :
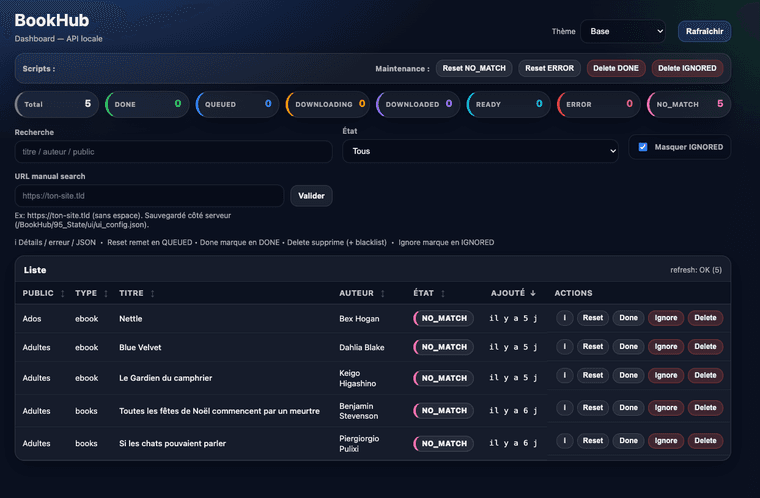
Gestion manuelle des livres- Marquer un livre en
DONEmanuellement (utile si Kavita ne le voit pas encore dans la bibliothèque). - Reset d’un livre : le repasse en
QUEUEDet le sort du mode “cooldown”
(cooldown = arrêt des recherches pendant 3 heures après 6 tentatives infructueuses). - Supprimer un livre ou le passer en
IGNORED:- ne plus le rechercher,
- ne plus l’afficher dans le dashboard,
- l’ajouter à la blacklist pour qu’il ne revienne pas, même s’il est toujours présent dans la wishlist.
Nouvel état : NO_MATCH- Introduction de l’état
NO_MATCHquand BookHub ne trouve aucun résultat pour un livre.
🧰 Barre d’actions globale (top bar)
Une barre d’actions en haut du dashboard permet des opérations “en masse” :
- Reset
NO_MATCH→ tous les livresNO_MATCHrepassent enQUEUED - Reset
ERROR→ tous les livresERRORrepassent enQUEUED - Delete
DONE→ supprime du dashboard tous les livresDONE - Delete
IGNORED→ supprime du dashboard tous les livresIGNORED
 Recherche manuelle (Anna)
Recherche manuelle (Anna)- Possibilité de lancer une recherche manuelle sur un titre ou un auteur.
- L’URL source est définie en haut de la page et peut être modifiée.
- Raccourcis :
- clic sur le titre → recherche Titre + Auteur sur Anna (nouvel onglet)
- clic sur l’auteur → recherche Auteur sur Anna (nouvel onglet)
 CSS & interface
CSS & interface- Ajout d’une liste de sélection de thème CSS.
Fonctionnel, mais les thèmes alternatifs sont encore incomplets / moches pour le moment. - Divers ajustements et améliorations CSS.
 Correctifs
Correctifs- Quelques bugs ont été corrigés au passage.
En tout 156 ebooks ont été téléchargés via BookHub, ce qui a permis de régler pas mal de soucis. Ce n’est pas parfait, mais c’est pas mal
Si un dev jetait un oeil au code, il ferait probablement une crise cardiaque

- Marquer un livre en
-
[Docker Apps] BookHub : Automatisation DL ebooks et traitementEncore des évolutions. Je ne sais plus à quelle version de BookHub j’en suis ^^
Le projet est presque reparti de 0, car débugguer des scripts Python qui se lancent à la chaine et une interface web, certes jolies, mais pas si fonctionnelle… J’ai changé de fusil d’épaule. Les outils ont aussi changés :- de ChatGPT à Claude pour le dev
- de Excel à Baserow auto-hébergé pour la wishlist
- de scripts Python à n8n pour automatiser
L’idée était aussi d’automatiser encore plus. Plutôt que d’intégrer manuellement les données dans la wishlist (synopsis, ISBN, etc…), j’envoie via Talk (ordi ou smartphone) Titre - Nom auteur, Prénom auteur et tout le reste se fait automatiquement. Après plus de 200 tests, ça tourne assez bien.
Je laisse tomber pour le moment l’UI, qui est certes jolies, mais moins pratique que Baserow. Je gagne encore un peu de temps avec ce fonctionnement, qui va être améliorer.
BookHub — Automatisation complète de ma bibliothèque d’ebooksProjet perso que je partage : une pipeline qui transforme un simple message en fiche livre complète, entièrement automatisée sur mon NAS.
Stack technique
Composant Rôle n8n Orchestration de toute la pipeline Python / FastAPI Scraper maison pour les métadonnées enrichies Ollama + Qwen 2.5 LLM local — génération de synopsis en dernier recours Baserow Base de données, source de vérité Nextcloud Talk Interface d’entrée (mobile + desktop) UnRAID Infrastructure NAS, tous les containers tournent là
L’idée
Envoyer un message depuis mon téléphone, et que tout le reste soit automatique.
Moi (Nextcloud Talk) : "Perfect enemies - Eilema Decker" BookHub : ✅ Fiche créée — Hillmore University #1 — ISBN 9782017258421
Comment ça marche
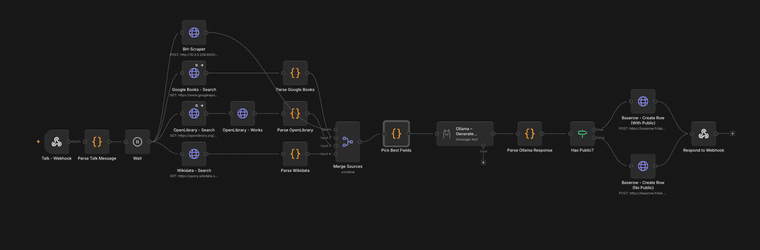
1. Déclenchement
J’envoie un message dans Nextcloud Talk avec le format
Titre - Auteur. Un webhook n8n capte le message et lance le pipeline.2. Recherche parallèle
Le pipeline interroge simultanément plusieurs sources : Google Books, OpenLibrary, Wikidata, et un scraper maison. Chacune excelle dans un domaine différent, ce qui permet de croiser les résultats.
3. Fusion intelligente
Chaque champ est renseigné depuis la meilleure source disponible :
Champ Priorité des sources Synopsis Scraper > OpenLibrary > Google Books FR > Google Books EN > Ollama ISBN Wikidata > Scraper > OpenLibrary > Google Books Série Wikidata > Scraper > Google Books > OpenLibrary Numéro de tome Wikidata > Scraper > Google Books > OpenLibrary Si aucune source ne trouve le synopsis, Ollama prend le relais et en génère un localement.
4. Enregistrement
La fiche complète est enregistrée dans Baserow, prête pour le workflow de téléchargement.
Résultats sur ~200 livres testés
Champ Taux de réussite Synopsis ~90% ISBN ~95% Série + numéro de tome ~85%
Workflow n8n
-
L’administration française va abandonner Windows ? C'est pas gagné...Parfois les reproches sont à faire du côté de la gestion de l’informatique et du comportement avec les utilisateurs. J’ai constaté trop souvent que ce n’était pas top, alors forcément, côté utilisateurs, il n’y a pas une bonne image de l’informatique et tout les comportements qui vont avec lorsqu’il y a peu de respect. Et non, je ne suis pas prof, mais côté informatique et travaille dans des écoles
Si chaque côté y met du sien, ça se passe bien, mais il faut communiquer. Des c… il y en a partout et on ne les changera pas, mais si ça fonctionne bien avec une majorité, c’est suffisant. Se passer de Windows est faisable. Ca prendra du temps, mais la gestion de Windows en bouffe beaucoup aussi
Il faut prévoir les budgets pour le début, mais sur du moyen/long terme, ça ne peut qu’être moins cher et plus stable. Si c’est bien géré, évidemment. -
[Tendance No Kids] Exit les chiards hurlants…@Ern-Dorr a dit dans [Tendance No Kids] Exit les chiards hurlants… :
TGV : 8% des places proposées du Lundi au Vendredi “no kids”!
Franchement une tempête dans un verre d’eau et des polémiques débiles.
Si c’était le train entier je pourrais comprendre mais 8%, sans déconner !Il y a sûrement des sujets beaucoup plus importants à traiter.

On pourrait faire “no ado”, parce que ceux qui mettent de la musique sans écouteurs, c’est pénible…
“no” mamie" aussi, parce que suivre les conversations sur ces petits enfants dont tout le wagon en profite…
“no beauf”, parce que regarder un match dans le train, sans écouteurs et en faisant profiter les autres de ses récations…
“no vieux” surtout, comme ça si on est assis, pas besoin de laisser sa place! Faut pas déconner.
En fait, des wagons vides, comme ça “no problem”
Dans “transport public”, il y a “public”
-
[Topic Unique] Les films que vous avez aimés et/ou adorésActuellement je montre à mes enfants et/ou ma femme des films qui m’ont marqués ou parfois nous les découvrons ensembles. Dernièrement nous en avons vu quelques-uns.
Titre : Contact

Synopsis :
Ellie Arroway, passionnée depuis sa plus tendre enfance par l’univers, est devenue une jeune et brillante astronome. Avec une petite équipe de chercheurs elle écoute le ciel et guette un signe d’intelligence extraterrestre. Un jour, ils captent un message.Avis :
Je l’ai revu avec ma plus grande fille. Il a une ambiance particulière, pesante par moment, intrigante à d’autres. Une ambiance que l’on ne retrouve plus dans les films bien plus récents. De la science fiction, du complot, du fanatisme et Jodie Foster au casting (est un argument en soit!).
Pour la fin, sortez les mouchoirs!Ce film fait parti de mon top 5, juste après Usual Suspects
-
[Aide] seed qBittorrent depuis changement carte réseau -
L’administration française va abandonner Windows ? C'est pas gagné...Anticiper, préparer, expliquer, documenter. Ca fonctionne. Oublier et/ou partiellement le faire : résistances, lenteurs, problèmes, mauvaise adoption et volonté,…
Faut pas que l’informatique oublie que c’est au service de ses utilisateurs (jusqu’à une certaine limite) et que les utilisateurs comprennent qu’il faut un temps d’adaptation. Meilleures sont les relations entre les deux groupes et mieux ça se passer
Il y a tellement de façon de simplifier la vie d’un utilisateur pour que ça se passe bien.
Dans une école où j’étais, suite à diverses “tensions”, un groupe de travaille a été créé (direction, profs, informatique) et à la suite de ça, ça a extrêmement bien fonctionné durant des années.