

Les moteurs de recherche IA citent des sources incorrectes à un taux alarmant de 60 %, selon une étude
-
Une étude du CJR montre que les services de recherche d’IA désinforment les utilisateurs et ignorent les demandes d’exclusion des éditeurs.
Une nouvelle étude du Tow Center for Digital Journalism de la Columbia Journalism Review révèle de sérieux problèmes de précision avec les modèles d’IA génératifs utilisés pour la recherche d’informations. L’étude a testé huit outils de recherche pilotés par l’IA et dotés d’une fonctionnalité de recherche en direct et a révélé que les modèles d’IA répondaient incorrectement à plus de 60 % des requêtes concernant les sources d’information.
Les chercheuses Klaudia Jaźwińska et Aisvarya Chandrasekar ont souligné dans leur rapport qu’environ un Américain sur quatre utilise désormais des modèles d’IA comme alternative aux moteurs de recherche traditionnels. Cela soulève de sérieuses inquiétudes quant à la fiabilité, compte tenu du taux d’erreur important révélé par l’étude.
Les taux d’erreur variaient considérablement selon les plateformes testées. Perplexity a fourni des informations erronées dans 37 % des requêtes testées, tandis que ChatGPT Search a identifié incorrectement 67 % (134 sur 200) des articles interrogés. Grok 3 a affiché le taux d’erreur le plus élevé, soit 94 %.
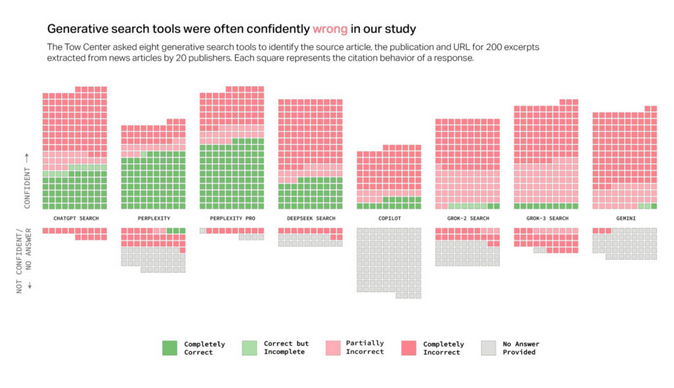
Un graphique du CJR montre des résultats de recherche « erronés »Pour les tests, les chercheurs ont fourni des extraits directs d’articles de presse aux modèles d’IA, puis ont demandé à chaque modèle d’identifier le titre de l’article, l’éditeur original, la date de publication et l’URL. Ils ont effectué 1 600 requêtes sur huit outils de recherche générative différents.
L’étude a mis en évidence une tendance commune à ces modèles d’IA : plutôt que de refuser de répondre lorsqu’ils manquaient d’informations fiables, les modèles fournissaient fréquemment des confabulations , c’est-à-dire des réponses erronées ou spéculatives, semblant plausibles. Les chercheurs ont souligné que ce comportement était cohérent avec tous les modèles testés, et non limité à un seul outil.
Étonnamment, les versions payantes premium de ces outils de recherche IA ont obtenu des résultats encore plus mauvais à certains égards. Perplexity Pro (20 $/mois) et le service premium de Grok 3 (40 $/mois) ont fourni des réponses incorrectes plus souvent que leurs homologues gratuits. Bien que ces modèles premium aient répondu correctement à un plus grand nombre de questions, leur réticence à refuser les réponses incertaines a entraîné des taux d’erreur globaux plus élevés.
Problèmes liés aux citations et au contrôle des éditeurs
Les chercheurs du CJR ont également découvert des preuves suggérant que certains outils d’IA ignoraient les paramètres du protocole d’exclusion des robots , utilisé par les éditeurs pour empêcher les accès non autorisés. Par exemple, la version gratuite de Perplexity a correctement identifié les 10 extraits de contenus National Geographic payants, malgré l’interdiction explicite des robots d’exploration de Perplexity par National Geographic.
Même lorsque ces outils de recherche IA citaient des sources, ils redirigeaient souvent les utilisateurs vers des versions syndiquées du contenu sur des plateformes comme Yahoo News plutôt que vers les sites des éditeurs d’origine. Ce phénomène se produisait même lorsque les éditeurs avaient des accords de licence formels avec des entreprises d’IA.
La fabrication d’URL est apparue comme un autre problème majeur. Plus de la moitié des citations issues de Google Gemini et Grok 3 ont conduit les utilisateurs vers des URL fabriquées ou rompues, générant des pages d’erreur. Sur 200 citations de Grok 3 testées, 154 ont abouti à des liens rompus.
Ces problèmes créent une tension importante pour les éditeurs, qui sont confrontés à des choix difficiles. Bloquer les robots d’exploration IA peut entraîner une perte totale d’attribution, tandis que les autoriser permet une réutilisation généralisée sans rediriger le trafic vers les sites web des éditeurs.
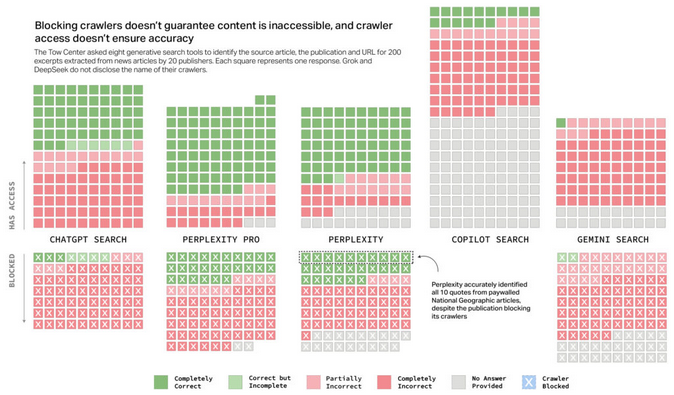
Un graphique de CJR montre que le blocage des robots d’exploration ne signifie pas que les moteurs de recherche IA acceptent la requête -sans blagues") -
-Mark Howard, directeur de l’exploitation du magazine Time, a exprimé à CJR ses inquiétudes quant à la transparence et au contrôle de l’affichage du contenu de Time via les recherches générées par l’IA. Malgré ces problèmes, Howard estime que des améliorations sont possibles pour les versions futures, déclarant : « Le produit est à son pire niveau aujourd’hui », citant des investissements et des efforts d’ingénierie considérables visant à améliorer ces outils.
Cependant, Howard a également fait honte aux utilisateurs, suggérant que c’est la faute de l’utilisateur s’il n’est pas sceptique quant à la précision des outils d’IA gratuits : « Si quelqu’un, en tant que consommateur, croit actuellement que l’un de ces produits gratuits sera précis à 100 %, alors honte à lui. »
OpenAI et Microsoft ont fait parvenir au CJR des déclarations accusant réception des conclusions, sans toutefois aborder directement les problèmes spécifiques. OpenAI a rappelé sa promesse de soutenir les éditeurs en générant du trafic grâce à des résumés, des citations, des liens clairs et des mentions d’origine. Microsoft a affirmé respecter les protocoles d’exclusion des robots et les directives des éditeurs.
Ce dernier rapport s’appuie sur les conclusions précédentes publiées par le Tow Center en novembre 2024, qui avaient identifié des problèmes de précision similaires dans la manière dont ChatGPT traitait les contenus d’actualité. Pour plus de détails sur ce rapport assez exhaustif, consultez le site web de Columbia Journalism Review.
Et si on réinjecte sur le web les conneries débitées par ces outils, ça ne va pas s’améliorer.
Bonjour ! Vous semblez intéressé par cette conversation, mais vous n’avez pas encore de compte.
Marre de refaire défiler les mêmes messages ? Créez un compte pour retrouver votre position, recevoir des notifications des nouvelles réponses, sauvegarder vos favoris et voter pour les messages que vous appréciez.
Grâce à votre participation, ce message peut devenir encore meilleur 💗
S'inscrire Se connecter