
Et si "l’IA" ne s’améliorait pas pour toujours ?
-
(Ou les limites de la non-intelligence en circuit fermé
") )
)De nouveaux rapports mettent en évidence les craintes de rendements décroissants pour la formation LLM traditionnelle.
Depuis des années, de nombreux observateurs du secteur de l’IA s’intéressent aux capacités croissantes des nouveaux modèles d’IA et réfléchissent à la poursuite de l’augmentation exponentielle des performances dans le futur . Cependant, récemment, une partie de cet optimisme en matière de « loi d’échelle » de l’IA a été remplacée par la crainte que nous puissions déjà atteindre un plateau dans les capacités des grands modèles de langage formés avec des méthodes standard.
Un rapport du week-end de The Information a résumé efficacement la façon dont ces craintes se manifestent chez un certain nombre d’initiés d’OpenAI. Des chercheurs anonymes d’OpenAI ont déclaré à The Information qu’Orion, le nom de code de la société pour son prochain modèle à part entière, montre une augmentation de performances plus faible que celle observée entre GPT-3 et GPT-4 ces dernières années. En fait, sur certaines tâches, le prochain modèle “n’est pas vraiment meilleur que son prédécesseur”, selon des chercheurs anonymes d’OpenAI cités dans l’article.
Lundi, Ilya Sutskever, co-fondateur d’OpenAI, qui a quitté l’entreprise plus tôt cette année , a ajouté aux inquiétudes selon lesquelles les LLM atteignaient un plateau dans ce qui pouvait être gagné grâce à la pré-formation traditionnelle. Sutskever a déclaré à Reuters que “les années 2010 étaient l’ère de la mise à l’échelle”, où l’ajout de ressources informatiques et de données de formation supplémentaires aux mêmes méthodes de formation de base pourrait conduire à des améliorations impressionnantes dans les modèles ultérieurs.
“Maintenant, nous sommes de retour à l’ère de l’émerveillement et de la découverte”, a déclaré Sutskever à Reuters. “Tout le monde recherche la prochaine chose. Il est plus que jamais important de mettre à l’échelle la bonne chose.”
Quelle est la prochaine étape ?
Une grande partie du problème de la formation, selon les experts et les initiés cités dans ces articles et dans d’autres, réside dans le manque de nouvelles données textuelles de qualité sur lesquelles les nouveaux LLM peuvent se former. À ce stade, les modélistes ont peut-être déjà choisi le fruit le plus bas parmi les vastes trésors de textes disponibles sur l’Internet public et les livres publiés.
Le cabinet de recherche Epoch AI a tenté de quantifier ce problème dans un article publié plus tôt cette année , mesurant le taux d’augmentation des ensembles de données de formation LLM par rapport au « stock estimé de textes publics générés par l’homme ». Après avoir analysé ces tendances, les chercheurs estiment que « les modèles linguistiques utiliseront pleinement ce stock [de textes publics générés par l’homme] entre 2026 et 2032 », laissant peu de piste précieuse pour simplement lancer davantage de données de formation sur le problème.
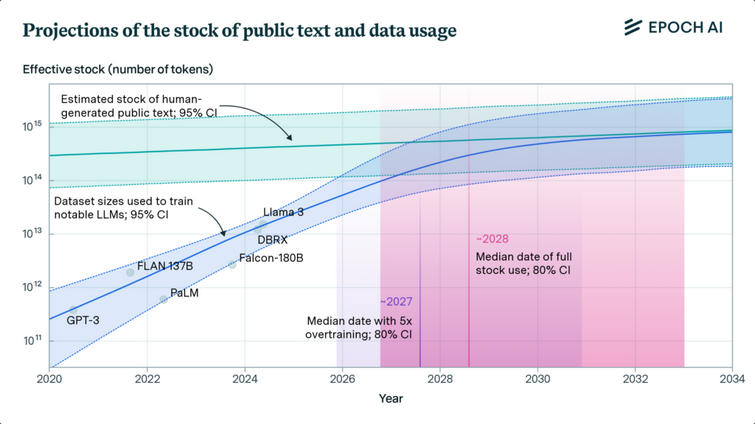
Les recherches d’Epoch AI suggèrent que les créateurs de LLM pourraient être complètement à court de données de formation textuelles publiques au cours des prochaines annéesOpenAI et d’autres sociétés ont déjà commencé à se tourner vers la formation sur des données synthétiques (créées par d’autres modèles) pour tenter de dépasser ce mur de formation qui approche à grands pas. Mais il existe important un débat sur la question de savoir si ce type de données artificielles peut conduire à un « effondrement du modèle » contextuel après quelques cycles d’entraînement récursif.
D’autres placent leurs espoirs dans les futurs modèles d’IA, basés sur l’amélioration des capacités de raisonnement plutôt que sur de nouvelles connaissances en matière de formation. Mais des recherches récentes montrent que les modèles de raisonnement actuels « de pointe » se laissent facilement tromper par des fausses pistes. D’autres chercheurs étudient également si un processus de distillation des connaissances peut aider les grands réseaux « d’enseignants » à former des réseaux « d’étudiants » avec un ensemble plus raffiné d’informations de qualité.
Mais si les méthodes actuelles de formation LLM commencent à plafonner, la prochaine grande avancée pourrait venir de la spécialisation. Microsoft, par exemple, a déjà connu un certain succès avec ce qu’on appelle les petits modèles de langage qui se concentrent sur des types spécifiques de tâches et de problèmes. Contrairement aux LLM généralistes auxquels nous sommes habitués aujourd’hui, nous pourrions voir dans un avenir proche des IA se concentrer sur des spécialisations de plus en plus étroites, un peu comme les doctorants forgent des voies plus nouvelles et plus ésotériques pour la connaissance humaine.
Source: https://arstechnica.com/ai/2024/11/what-if-ai-doesnt-just-keep-getting-better-forever/
“L’I.A.” par LLM, pas mieux qu’une voyante extra-lucide
Peut-être que l’auto apprentissage ira un peu plus loin, mais pour l’intelligence, passez votre chemin. -
Skynet va relever le niveau pas d’inquiétude