
La guerre de l’IA s’intensifie avec Claude 3, prétendument doté de capacités « quasi humaines »
-
Willison : “Aucun modèle n’a battu GPT-4 sur une gamme de tests largement utilisés comme celui-ci.”

Le logo Anthropic Claude 3.Lundi, Anthropic a publié Claude 3, une famille de trois modèles de langage d’IA similaires à ceux qui alimentent ChatGPT . Anthropic affirme que les modèles établissent de nouvelles références industrielles pour une gamme de tâches cognitives, se rapprochant même des capacités « quasi humaines » dans certains cas. Il est disponible dès maintenant sur le site Web d’Anthropic, le modèle le plus puissant étant uniquement disponible sur abonnement. Il est également disponible via API pour les développeurs.
Les trois modèles de Claude 3 représentent une complexité et un nombre de paramètres croissants : Claude 3 Haiku, Claude 3 Sonnet et Claude 3 Opus. Sonnet alimente désormais gratuitement le chatbot Claude.ai avec une connexion par e-mail. Mais comme mentionné ci-dessus, Opus n’est disponible via l’interface de chat Web d’Anthropic que si vous payez 20 $ par mois pour « Claude Pro », un service d’abonnement proposé via le site Web d’Anthropic. Tous les trois disposent d’une fenêtre contextuelle de 200 000 jetons. (La fenêtre contextuelle correspond au nombre de jetons (fragments d’un mot) qu’un modèle de langage d’IA peut traiter à la fois.)
Nous avons couvert le lancement de Claude en mars 2023 et de Claude 2 en juillet de la même année. À chaque fois, Anthropic s’est retrouvé légèrement en retrait des meilleurs modèles d’OpenAI en termes de capacités tout en les surpassant en termes de longueur de fenêtre contextuelle. Avec Claude 3, Anthropic a peut-être enfin rattrapé les modèles publiés par OpenAI en termes de performances, même s’il n’y a pas encore de consensus parmi les experts - et la présentation des benchmarks d’IA est notoirement encline à la sélection.
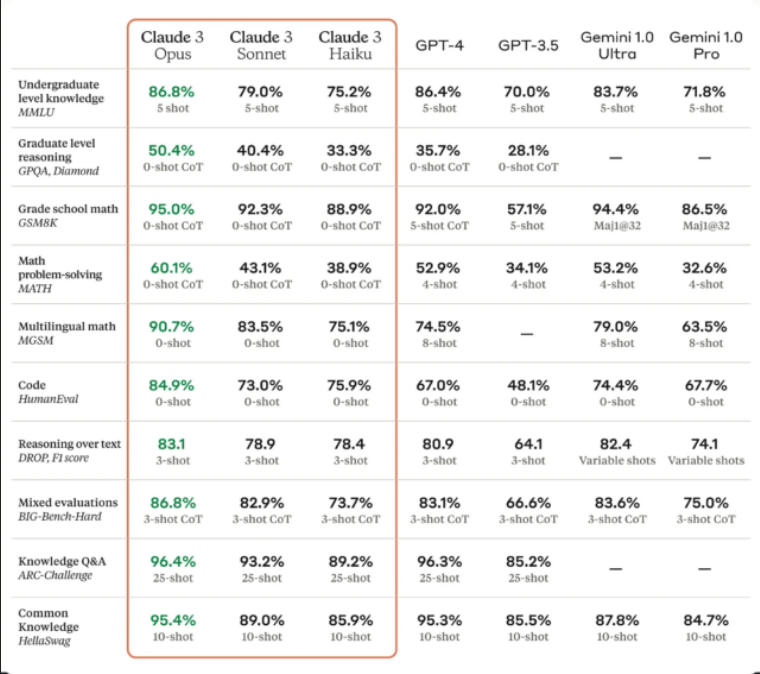
Un tableau de référence Claude 3 fourni par Anthropic.Claude 3 aurait démontré des performances avancées dans diverses tâches cognitives, notamment le raisonnement, les connaissances spécialisées, les mathématiques et la maîtrise du langage. (Malgré l’absence de consensus sur la question de savoir si les grands modèles de langage « savent » ou « raisonnent », la communauté des chercheurs en IA utilise couramment ces termes.) La société affirme que le modèle Opus, le plus performant des trois, présente des « niveaux quasi-humains ». de compréhension et d’aisance sur des tâches complexes.
C’est une affirmation assez entêtante et qui mérite d’être analysée avec plus d’attention. Il est probablement vrai qu’Opus est « quasi-humain » selon certains critères spécifiques, mais cela ne signifie pas qu’Opus est une intelligence générale comme un humain (considérez que les calculatrices de poche sont surhumaines en mathématiques). Il s’agit donc d’une affirmation volontairement accrocheuse qui peut être édulcorée par des réserves.
Selon Anthropic, Claude 3 Opus bat GPT-4 sur 10 tests d’IA, dont MMLU (connaissances de premier cycle), GSM8K (mathématiques à l’école primaire), HumanEval (codage) et HellaSwag (connaissance commune), au nom coloré. Plusieurs des victoires sont très étroites, comme 86,8 pour cent pour Opus contre 86,4 pour cent sur un essai en cinq coups de MMLU, et certains écarts sont importants, comme 90,7 pour cent sur HumanEval par rapport aux 67,0 pour cent de GPT-4. Mais il est difficile de dire ce que cela pourrait signifier exactement pour vous en tant que client.
“Comme toujours, les benchmarks LLM doivent être traités avec un peu de suspicion”, déclare le chercheur en IA Simon Willison , qui a parlé avec Ars à propos de Claude 3. "Les performances d’un modèle par rapport aux benchmarks ne vous disent pas grand-chose sur la façon dont le modèle ’ se sent "à utiliser. Mais cela reste une affaire énorme : aucun autre modèle n’a battu GPT-4 sur une gamme de tests de référence largement utilisés comme celui-ci. "
Une large gamme de prix et de performances
Par rapport à son prédécesseur, les modèles Claude 3 présentent des améliorations par rapport à Claude 2 dans des domaines tels que l’analyse, la prévision, la création de contenu, la génération de code et la conversation multilingue. Les modèles auraient également des capacités de vision améliorées, leur permettant de traiter des formats visuels tels que des photos, des graphiques et des diagrammes, similaires à GPT-4V (dans les versions d’abonnement de ChatGPT) et à Gemini de Google.
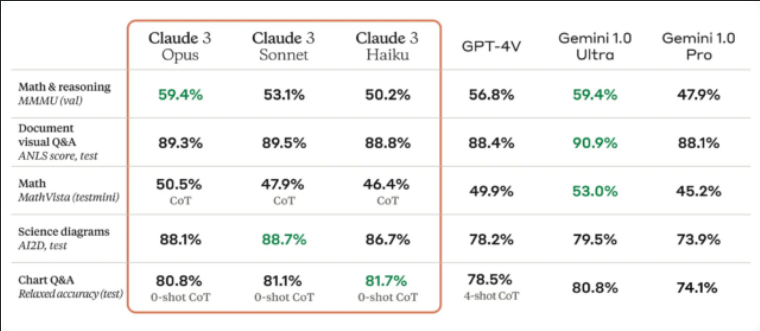
Un tableau de référence Claude 3 des capacités de vision multimodale fourni par Anthropic.Anthropic souligne la vitesse et la rentabilité accrues des trois modèles par rapport aux générations précédentes et aux modèles concurrents. Opus (le plus grand modèle) coûte 15 $ par million de jetons d’entrée et 75 $ par million de jetons de sortie, Sonnet (le modèle intermédiaire) coûte 3 $ par million de jetons d’entrée et 15 $ par million de jetons de sortie, et Haiku (le modèle le plus petit et le plus rapide) coûte 0,25 $ par million de jetons d’entrée. million de jetons d’entrée et 1,25 $ par million de jetons de sortie. d’OpenAI En comparaison, le GPT-4 Turbo via API coûte 10 $ par million de jetons d’entrée et 30 $ par million de jetons de sortie. GPT-3.5 Turbo coûte 0,50 $ par million de jetons d’entrée et 1,50 $ par million de jetons de sortie.
Lorsque nous avons interrogé Willison sur ses impressions sur les performances de Claude 3, il a répondu qu’il n’en avait pas encore eu une idée, mais que le prix API de chaque modèle avait immédiatement attiré son attention. “Le moins cher inédit semble radicalement compétitif”, déclare Willison. “La meilleure qualité est très chère.”
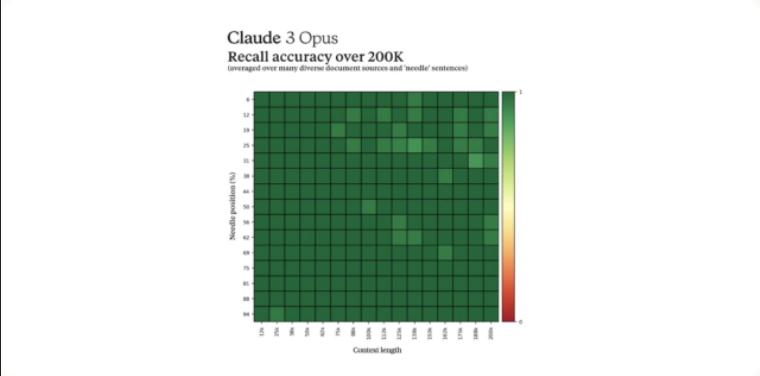
Dans d’autres notes diverses, les modèles Claude 3 pourraient gérer jusqu’à 1 million de jetons pour certains clients (similaires à Gemini Pro 1.5 ), et Anthropic affirme que le modèle Opus a atteint un rappel presque parfait lors d’un test de référence sur cette taille de contexte massive, dépassant 99 pour cent de précision. En outre, la société affirme que les modèles Claude 3 sont moins susceptibles de refuser des invites inoffensives et font preuve d’une plus grande précision tout en réduisant les réponses incorrectes.
Selon une fiche modèle publiée avec les modèles, Anthropic a obtenu les gains de capacités de Claude 3 en partie grâce à l’utilisation de données synthétiques dans le processus de formation. Les données synthétiques désignent les données générées en interne à l’aide d’un autre modèle de langage d’IA, et la technique peut servir à élargir la profondeur des données de formation pour représenter des scénarios qui pourraient manquer dans un ensemble de données récupérées. “La question des données synthétiques est un gros problème”, déclare Willison.
Un tableau de référence Claude 3 fourni par Anthropic.Anthropic prévoit de publier des mises à jour fréquentes de la famille de modèles Claude 3 dans les mois à venir, ainsi que de nouvelles fonctionnalités telles que l’utilisation d’outils, le codage interactif et les « capacités agentiques avancées ». L’entreprise affirme qu’elle reste déterminée à garantir que les mesures de sécurité suivent le rythme des progrès en matière de performances de l’IA et que les modèles Claude 3 “présentent actuellement un potentiel négligeable de risque catastrophique”.
Les modèles Opus et Sonnet sont désormais disponibles via l’API d’Anthropic, et Haiku suivra bientôt. Sonnet est également accessible via Amazon Bedrock et en avant-première privée sur Vertex AI Model Garden de Google Cloud.
Un mot sur les benchmarks LLM
Nous nous sommes inscrits à Claude Pro pour essayer Opus par nous-mêmes avec quelques tests informels. Opus semble similaire en termes de capacités à ChatGPT-4. Il ne peut pas écrire des blagues originales sur les papas (toutes semblent avoir été récupérées sur le Web), il est plutôt bon pour résumer des informations et composer du texte dans différents styles, il s’en sort plutôt bien dans l’analyse logique des problèmes de mots, et les confabulations semblent en effet relativement faibles. (mais nous en avons vu quelques-uns se glisser en posant des questions sur des sujets plus obscurs).
Rien de tout cela n’est une réussite ou un échec définitif, et cela peut être frustrant dans un monde où les produits informatiques produisent généralement des chiffres précis et des références quantifiables. “Encore un autre cas de” vibrations “en tant que concept clé de l’IA moderne”, nous a expliqué Willison.

Les benchmarks d’IA sont délicats car l’efficacité de tout assistant d’IA est très variable en fonction des invites utilisées et du conditionnement du modèle d’IA sous-jacent. Les modèles d’IA peuvent donner de bons résultats « au test » (pour ainsi dire), mais ne parviennent pas à généraliser ces capacités à de nouvelles situations.
De plus, l’efficacité de l’assistant IA est très subjective (d’où les « vibrations » de Willison). En effet, il est difficile de quantifier (par exemple, dans une mesure de référence) qu’un modèle d’IA réussisse à faire ce que vous voulez faire, alors que la tâche que vous lui confiez peut être littéralement n’importe quelle tâche dans n’importe quel domaine intellectuel sur terre. Certains modèles fonctionnent bien pour certaines tâches et pas pour d’autres, et cela peut varier d’une personne à l’autre en fonction de la tâche et du style d’incitation.
Cela vaut pour chaque grand modèle de langage proposé par des fournisseurs tels que Google, OpenAI et Meta, et pas seulement pour Claude 3. Au fil du temps, les gens ont découvert que chaque modèle avait ses propres particularités, et que les forces et les faiblesses de chaque modèle pouvaient être adoptées ou contournées en utilisant certaines techniques d’incitation. À l’heure actuelle, il semble que les principaux assistants d’IA s’installent dans une suite de fonctionnalités très similaires.
Et donc, le point de tout cela est que quand Anthropic dit que Claude 3 peut surpasser GPT-4 Turbo, qui est actuellement encore largement considéré comme le leader du marché en termes de capacité générale et de faibles hallucinations, il faut prendre cela avec un peu de prudence. de sel ou une dose de vibrations. Si vous envisagez différents modèles, il est essentiel de tester personnellement chaque modèle pour voir s’il correspond à votre application, car il est probable que personne d’autre ne puisse reproduire l’ensemble exact des circonstances dans lesquelles vous l’utiliseriez.
Cela vaut pour chaque grand modèle de langage proposé par des fournisseurs tels que Google, OpenAI et Meta, et pas seulement pour Claude 3. Au fil du temps, les gens ont découvert que chaque modèle avait ses propres particularités, et que les forces et les faiblesses de chaque modèle pouvaient être adoptées ou contournées en utilisant certaines techniques d’incitation. À l’heure actuelle, il semble que les principaux assistants d’IA s’installent dans une suite de fonctionnalités très similaires.
Et donc, le point de tout cela est que quand Anthropic dit que Claude 3 peut surpasser GPT-4 Turbo, qui est actuellement encore largement considéré comme le leader du marché en termes de capacité générale et de faibles hallucinations, il faut prendre cela avec un peu de prudence. de sel ou une dose de vibrations. Si vous envisagez différents modèles, il est essentiel de tester personnellement chaque modèle pour voir s’il correspond à votre application, car il est probable que personne d’autre ne puisse reproduire l’ensemble exact des circonstances dans lesquelles vous l’utiliseriez.
Le terme Intelligence artificielle devrait être définitivement banni pour les modèles prédictifs.
Bonjour ! Vous semblez intéressé par cette conversation, mais vous n’avez pas encore de compte.
Marre de refaire défiler les mêmes messages ? Créez un compte pour retrouver votre position, recevoir des notifications des nouvelles réponses, sauvegarder vos favoris et voter pour les messages que vous appréciez.
Grâce à votre participation, ce message peut devenir encore meilleur 💗
S'inscrire Se connecter