
Tout le monde parle de Mistral, un nouveau challenger français d'OpenAI
-
Lundi, Mistral AI a annoncé un nouveau modèle de langage d’IA appelé Mixtral 8x7B, un modèle de « mélange d’experts » (MoE) avec des pondérations ouvertes qui correspondrait véritablement au GPT-3.5 d’OpenAI en termes de performances – une réalisation qui a été revendiquée par d’autres dans le passé. mais il est pris au sérieux par des poids lourds de l’IA tels que Andrej Karpathy et Jim Fan d’OpenAI . Cela signifie que nous sommes plus près d’avoir un assistant IA de niveau ChatGPT-3.5 qui peut fonctionner librement et localement sur nos appareils, à condition d’être correctement implémenté.
Mistral, basée à Paris et fondée par Arthur Mensch, Guillaume Lampe et Timothée Lacroix, a récemment connu une croissance rapide dans le domaine de l’IA. Elle a rapidement levé du capital-risque pour devenir une sorte d’anti-OpenAI français, défendant des modèles plus petits aux performances accrocheuses. Plus particulièrement, les modèles de Mistral s’exécutent localement avec des pondérations ouvertes qui peuvent être téléchargées et utilisées avec moins de restrictions que les modèles d’IA fermés d’OpenAI, Anthropic ou Google. (Dans ce contexte, les « poids » sont les fichiers informatiques qui représentent un réseau neuronal entraîné.)
Mixtral 8x7B peut traiter une fenêtre contextuelle de token de 32 Ko et fonctionne en français, allemand, espagnol, italien et anglais. Il fonctionne un peu comme ChatGPT dans la mesure où il peut aider aux tâches de composition, analyser les données, dépanner les logiciels et écrire des programmes. Mistral affirme qu’il surpasse le LLaMA 2 70B (70 milliards de paramètres) grand modèle de langage beaucoup plus grand de Meta et qu’il correspond ou dépasse le GPT-3.5 d’OpenAI sur certains benchmarks, comme le montre le tableau ci-dessous.
Un tableau des performances du Mixtral 8x7B par rapport à LLaMA 2 70B et GPT-3.5, fourni par Mistral.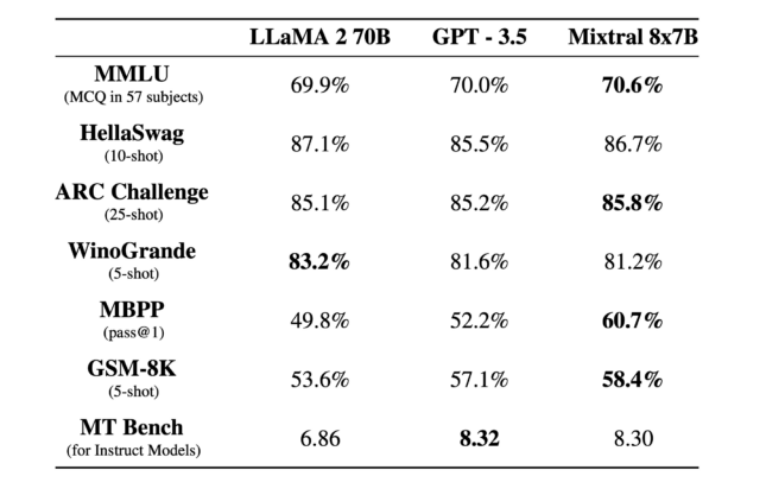
Un tableau des performances du Mixtral 8x7B par rapport à LLaMA 2 70B et GPT-3.5, fourni par Mistral.La vitesse à laquelle les modèles d’IA à pondération ouverte ont rattrapé l’offre phare d’OpenAI il y a un an en a surpris plus d’un. Pietro Schirano, le fondateur d’EverArt, a écrit sur X : “Tout simplement incroyable. J’utilise Mistral 8x7B instru à 27 jetons par seconde, entièrement localement grâce à @LMStudioAI. Un modèle qui obtient de meilleurs résultats que GPT-3.5, localement. Imaginez où nous ce sera dans 1 an.”
Le fondateur de LexicaArt, Sharif Shameem , a tweeté : « Le modèle Mixtral MoE ressemble véritablement à un point d’inflexion – un véritable modèle de niveau GPT-3.5 qui peut fonctionner à 30 jetons/s sur un M1. Imaginez tous les produits désormais possibles lorsque l’inférence est 100 % gratuite et vos données restent sur votre appareil." Ce à quoi Andrej Karpathy a répondu : “D’accord. On a l’impression que la capacité/le pouvoir de raisonnement a fait des progrès majeurs, le retard est davantage lié à l’UI/UX de l’ensemble, peut-être qu’un outil utilise un réglage fin, peut-être des bases de données RAG, etc.”
Mélange d’experts
Alors, que signifie le mélange d’experts ? Comme l’explique cet excellent guide Hugging Face , il fait référence à une architecture de modèle d’apprentissage automatique dans laquelle un réseau de portes achemine les données d’entrée vers différents composants de réseau neuronal spécialisés, appelés « experts », pour traitement. L’avantage est que cela permet une formation et une inférence de modèles plus efficaces et évolutives, car seul un sous-ensemble d’experts est activé pour chaque entrée, ce qui réduit la charge de calcul par rapport aux modèles monolithiques avec un nombre de paramètres équivalent.
En termes simples, un ministère de l’Environnement, c’est comme avoir une équipe de travailleurs spécialisés (les « experts ») dans une usine, où un système intelligent (le « réseau de portes ») décide quel travailleur est le mieux placé pour gérer chaque tâche spécifique. Cette configuration rend l’ensemble du processus plus efficace et plus rapide, car chaque tâche est effectuée par un expert dans ce domaine, et tous les travailleurs n’ont pas besoin d’être impliqués dans chaque tâche, contrairement à une usine traditionnelle où chaque travailleur peut devoir effectuer un peu de travail. tout.
Selon certaines rumeurs , OpenAI utiliserait un système MoE avec GPT-4 , ce qui expliquerait une partie de ses performances. Dans le cas de Mixtral 8x7B, le nom implique que le modèle est un mélange de huit réseaux neuronaux de 7 milliards de paramètres, mais comme Karpathy l’a souligné dans un tweet, le nom est légèrement trompeur car « ce ne sont pas tous les paramètres 7B qui sont étant 8x’d, seuls les blocs FeedForward dans le Transformer sont 8x’d, tout le reste reste le même. D’où aussi pourquoi le nombre total de paramètres n’est pas de 56B mais seulement de 46,7B."
Mixtral n’est pas le premier mélange « ouvert » de modèles experts, mais il se distingue par sa taille relativement petite en termes de nombre de paramètres et de performances. Il est maintenant disponible, disponible sur Hugging Face et BitTorrent sous la licence Apache 2.0. Les gens l’ont exécuté localement à l’aide d’une application appelée LM Studio . En outre, Mistral a commencé à proposer un accès bêta à une API pour trois niveaux de modèles Mistral.
Bonjour ! Vous semblez intéressé par cette conversation, mais vous n’avez pas encore de compte.
Marre de refaire défiler les mêmes messages ? Créez un compte pour retrouver votre position, recevoir des notifications des nouvelles réponses, sauvegarder vos favoris et voter pour les messages que vous appréciez.
Grâce à votre participation, ce message peut devenir encore meilleur 💗
S'inscrire Se connecter