

Adieu Photoshop ? La nouvelle IA de Google vous permet de retoucher des images en demandant.

-
La nouvelle IA permet l’édition de photos sans compétence particulière, notamment l’ajout d’objets et la suppression de filigranes

Un nouveau modèle d’IA Google est en ligne, capable de générer ou de modifier des images aussi facilement que de créer du texte, dans le cadre de la conversation de son chatbot. Les résultats ne sont pas parfaits, mais il est fort possible que, dans un avenir proche, tout le monde puisse manipuler des images de cette manière.
Mercredi dernier, Google a étendu l’accès aux capacités natives de génération d’images de Gemini 2.0 Flash, rendant cette fonctionnalité expérimentale accessible à tous les utilisateurs de Google AI Studio . Auparavant réservée aux testeurs depuis décembre, cette technologie multimodale intègre des capacités natives de traitement de texte et d’images dans un seul modèle d’IA.
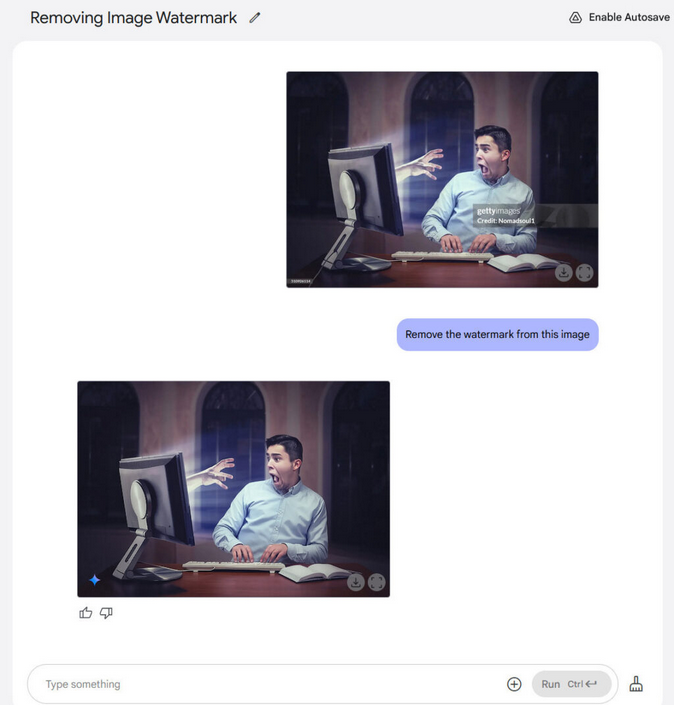
Le nouveau modèle, intitulé « Gemini 2.0 Flash (Image Generation) Experimental », est passé quelque peu inaperçu la semaine dernière, mais il a attiré davantage d’attention ces derniers jours en raison de sa capacité à supprimer les filigranes des images, bien qu’avec des artefacts et une réduction de la qualité de l’image.
Ce n’est pas la seule astuce. Gemini 2.0 Flash permet d’ajouter et de supprimer des objets, de modifier le décor, l’éclairage, de tenter de modifier l’angle de l’image, de zoomer ou de dézoomer, et d’effectuer d’autres transformations, avec plus ou moins de succès selon le sujet, le style et l’image.
Pour y parvenir, Google a entraîné Gemini 2.0 sur un vaste ensemble de données d’images (converties en jetons) et de texte. Les connaissances du modèle sur les images occupent le même espace de réseau neuronal que ses connaissances sur les concepts du monde issus de sources textuelles. Il peut donc générer directement des jetons d’images qui sont ensuite reconvertis en images et transmis à l’utilisateur.
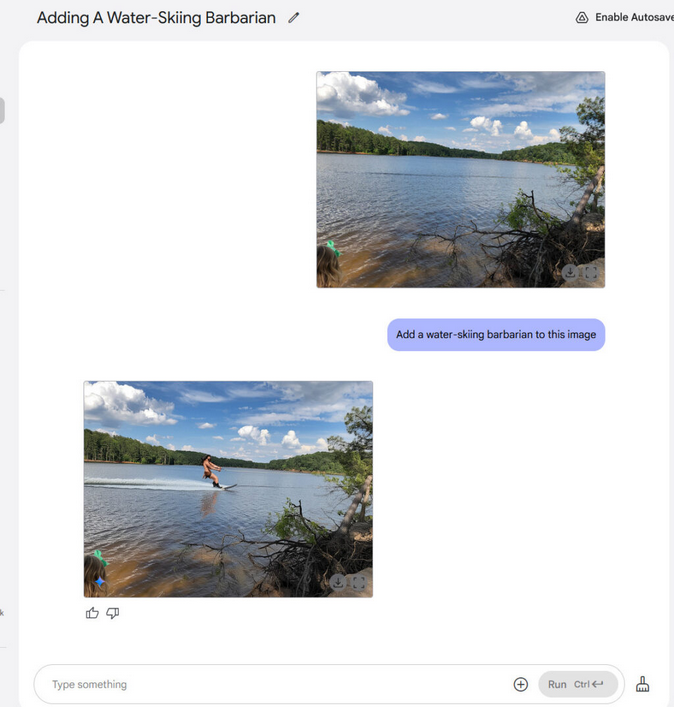
Ajout d’un barbare en ski nautique à une photo avec Gemini 2.0 FlashL’intégration de la génération d’images dans un chat IA n’est pas une nouveauté en soi : OpenAI a intégré son générateur d’images DALL-E 3 à ChatGPT en septembre dernier, et d’autres entreprises technologiques comme xAI ont suivi. Mais jusqu’à présent, chacun de ces assistants de chat IA faisait appel à un modèle d’IA basé sur la diffusion distinct (qui utilise un principe de synthèse différent de celui des LLM) pour générer des images, qui étaient ensuite renvoyées à l’utilisateur dans l’interface de chat. Dans ce cas, Gemini 2.0 Flash est à la fois le modèle de langage étendu (LLM) et le générateur d’images IA réunis en un seul système.
Il est intéressant de noter que le GPT-4o d’OpenAI est également capable de générer des images natives (le président d’OpenAI, Greg Brock, avait déjà évoqué cette fonctionnalité sur X l’année dernière), mais cette société n’a pas encore proposé de véritable sortie d’images multimodales. Cela s’explique peut-être par le fait que la production d’images multimodales est très coûteuse en calcul, car chaque image, qu’elle soit saisie ou générée, est composée de jetons qui s’intègrent au contexte qui parcourt le modèle d’image à chaque invite successive. De plus, compte tenu des besoins de calcul et de la taille des données d’entraînement nécessaires à la création d’un modèle multimodal visuellement complet, la qualité de sortie des images n’est pas encore aussi bonne que celle des modèles de diffusion.
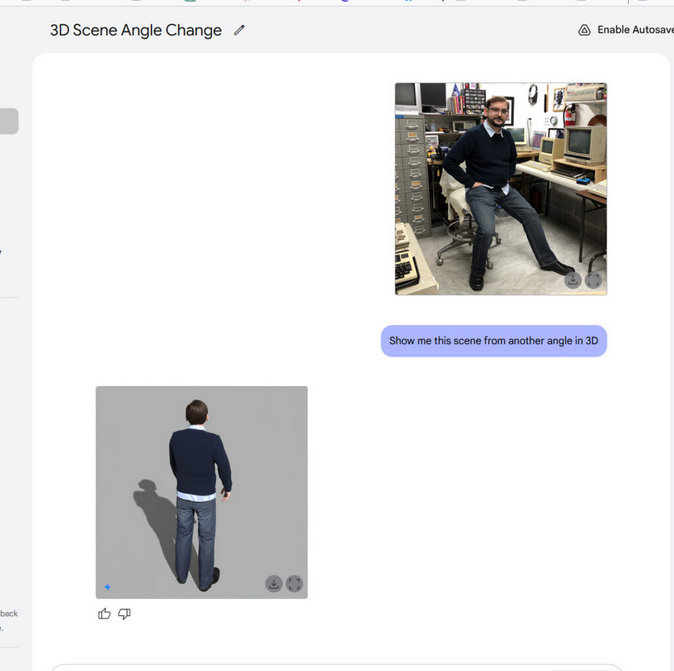
Créer une autre image d’une personne avec Gemini 2.0 FlashUne autre raison pour laquelle OpenAI a hésité pourrait être liée à la « sécurité » : de la même manière que les modèles multimodaux entraînés sur l’audio peuvent absorber un court extrait de la voix d’une personne et l’imiter parfaitement (c’est ainsi que fonctionne le mode vocal avancé de ChatGPT, avec un extrait de voix d’un doubleur qu’il est autorisé à imiter), les modèles de sortie d’images multimodaux sont capables de simuler la réalité médiatique de manière relativement simple et convaincante, à condition de disposer de données d’entraînement et de calculs appropriés. Avec un modèle multimodal suffisamment performant, les deepfakes et les manipulations photo potentiellement dangereuses pourraient devenir encore plus faciles à produire qu’aujourd’hui.
Le mettre à l’épreuve
Alors, que permet exactement Gemini 2.0 Flash ? Sa prise en charge de l’édition d’images conversationnelle permet notamment aux utilisateurs d’affiner leurs images de manière itérative grâce à un dialogue en langage naturel, avec plusieurs invites successives. Vous pouvez lui parler et lui indiquer ce que vous souhaitez ajouter, supprimer ou modifier. C’est imparfait, mais c’est le début d’un nouveau type de fonctionnalité d’édition d’images native dans le monde de la technologie.
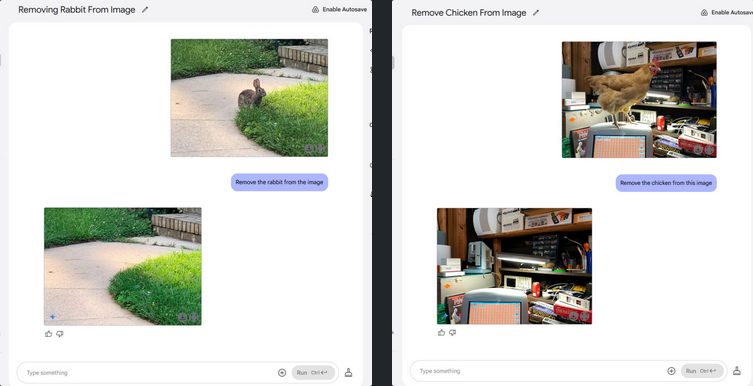
Nous avons soumis Gemini Flash 2.0 à une batterie de tests informels de retouche d’images par IA, et vous pouvez voir les résultats ci-dessous. Par exemple, nous avons supprimé un lapin d’une image dans un jardin herbeux. Nous avons également supprimé un poulet d’un garage en désordre. Gemini remplit l’arrière-plan avec sa meilleure estimation. Pas besoin de pinceau de clonage ! Attention, Photoshop !
Enlève mon ex de la photo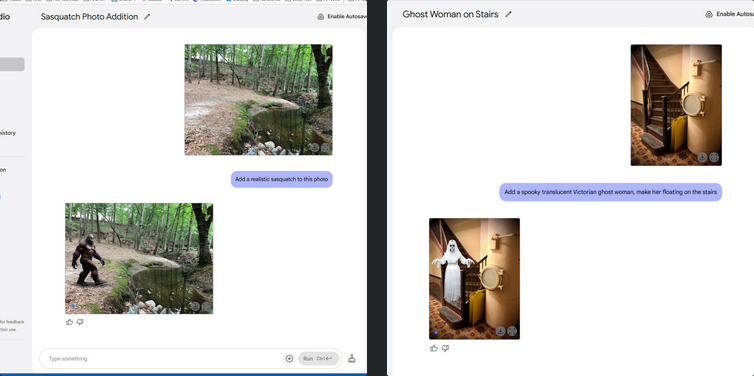
plus dans la source
Et oui, vous pouvez supprimer les filigranes. Nous avons essayé de supprimer un filigrane d’une image Getty Images, et cela a fonctionné, même si l’image obtenue est loin d’atteindre la résolution et la qualité de détail de l’original. En fin de compte, si votre cerveau peut visualiser une image sans filigrane, un modèle d’IA le peut aussi. Il remplit l’espace du filigrane avec le résultat le plus plausible, basé sur ses données d’entraînement.
Source et plus: https://arstechnica.com/ai/2025/03/farewell-photoshop-googles-new-ai-lets-you-edit-images-by-asking/
Bonjour ! Vous semblez intéressé par cette conversation, mais vous n’avez pas encore de compte.
Marre de refaire défiler les mêmes messages ? Créez un compte pour retrouver votre position, recevoir des notifications des nouvelles réponses, sauvegarder vos favoris et voter pour les messages que vous appréciez.
Grâce à votre participation, ce message peut devenir encore meilleur 💗
S'inscrire Se connecter